人工智能基本理论及应用研究综述
1. 知识表示与推理
1.1 知识与知识表示
什么是知识?知识的特点有哪些?
知识是指人类对事物的认识和理解。在人工智能领域,知识可以指代计算机系统所拥有的信息和经验,可以是经过系统化处理的结构化信息,也可以是非结构化信息,如自然语言文本或图像。
知识具有以下特点:
- 知识是有用的:知识不仅仅是信息,而是对信息的理解和解释,能够帮助人们解决问题、制定决策、或完成任务。
- 知识是有结构的:知识是有组织的,可以用不同的方法表示,如逻辑规则、概念图、本体论、或神经网络。
- 知识是可传递的:知识可以通过各种方式传递给他人,如文字、图像、语音、或代码。
- 知识是动态的:知识是不断变化的,随着新信息的获取和理解,知识也会发生改变。
- 知识是主观的:知识受到个人的认识和理解,不同的人可能会对同一件事物持有不同的知识。
什么是知识表示?现有知识表示方法特点及其应用等方面的对比(字数200-350字)
知识表示是指如何将知识存储在计算机系统中,并使计算机系统能够理解和使用这些知识的领域。知识表示的目的是为了方便计算机理解和处理知识,为人工智能的应用提供技术支持。
下面是符号化知识表示方法和数值型知识表示方法的对比表格:
| 类别 | 符号化知识表示方法 | 数值型知识表示方法 |
|---|---|---|
| 知识表示形式 | 使用符号(文字、符号或图形)表示知识 | 使用数值(数字、向量或矩阵)表示知识 |
| 应用场景 | 适用于表示复杂的知识结构和概念之间的关系 | 适用于使用数据挖掘和机器学习技术进行知识提取和分析,并且能够在大规模的知识库中快速查询 |
| 代表性方法 | 一阶谓词逻辑、产生式表示法、框架表示法、知识图谱 | 数值化向量知识表示、神经网络、矩阵分解、潜在语义分析等 |
| 优点 | 可以使用逻辑推理进行知识推理,易于人类理解,更具有可解释性 | 易于捕获隐藏的、不易于明确表示的知识,更易于机器处理 |
- 一阶谓词逻辑常用于表示复杂的知识结构和概念之间的关系,例如在自然语言处理领域中,可以使用一阶谓词逻辑表示句子之间的关系,使用逻辑推理进行知识推理,如判断句子之间的先后顺序或辨别句子之间的因果关系。
- 产生式表示法常用于表示语言的知识,例如在自然语言处理领域中,可以使用产生式表示法来表示句子的语法结构,例如分析句子的主谓宾结构或判断句子的合法性。
- 框架表示法常用于表示概念的知识,例如在概念图中,可以使用框架表示法来表示概念的结构和属性,如描述概念的类别、属性和关系等。
- 知识图谱常用于表示知识的结构和关系,例如在生物学领域中,可以使用知识图谱来表示生物物种之间的系统发育关系或表示蛋白质功能之间的相互作用关系;在知识管理领域中,可以使用知识图谱来表示企业内部员工的专业知识或表示企业与客户之间的交互关系等。
1.2 确定性推理
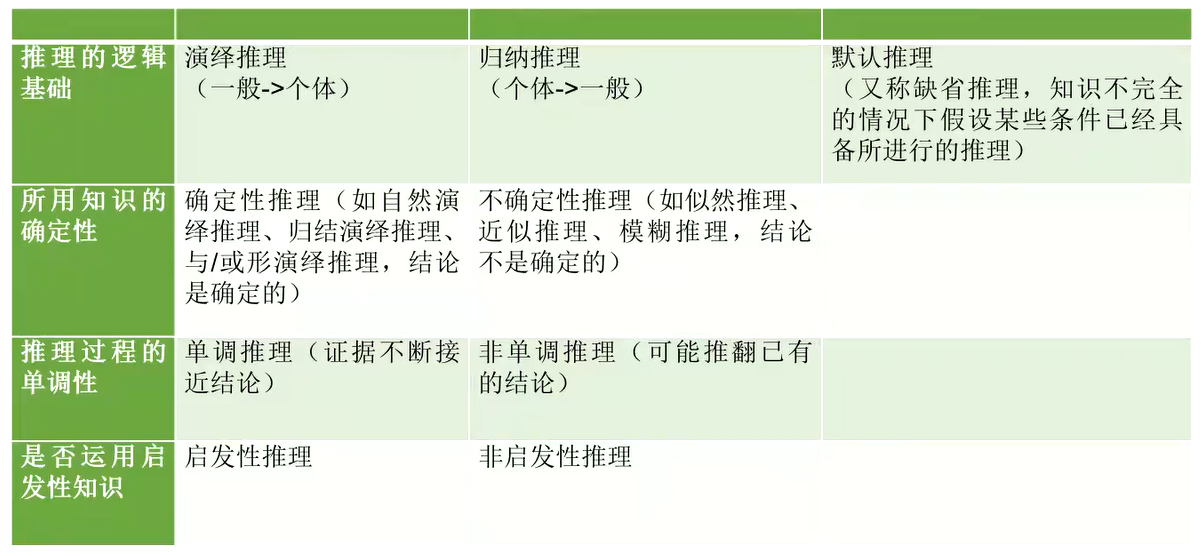
什么是确定性推理?其主要特点是什么?
确定性推理是指在已知条件下,通过一定的推理方法,推导出结论的过程。确定性推理假设所有的条件和规则都是确定的,并以一种唯一的方式进行推理。
确定性推理具有以下特点:
- 确定性推理以确定的条件和规则为基础,并在此基础上进行推理。
- 确定性推理的结果是唯一的,在相同的条件和规则下,确定性推理的结果是不变的。
- 确定性推理是一种逻辑推理,它能够帮助我们更好地理解知识之间的关系,并为我们提供解决问题的方法。
- 确定性推理通常用于专家系统、决策支持系统等应用中,能够帮助我们在复杂的环境中做出正确的决策。
**介绍一种确定性推理方法及其在实际问题中的应用(要求:参考文献年份为2017-2022年),并对该推理方法的优缺点及适用领域进行分析。(字数300-500字) **
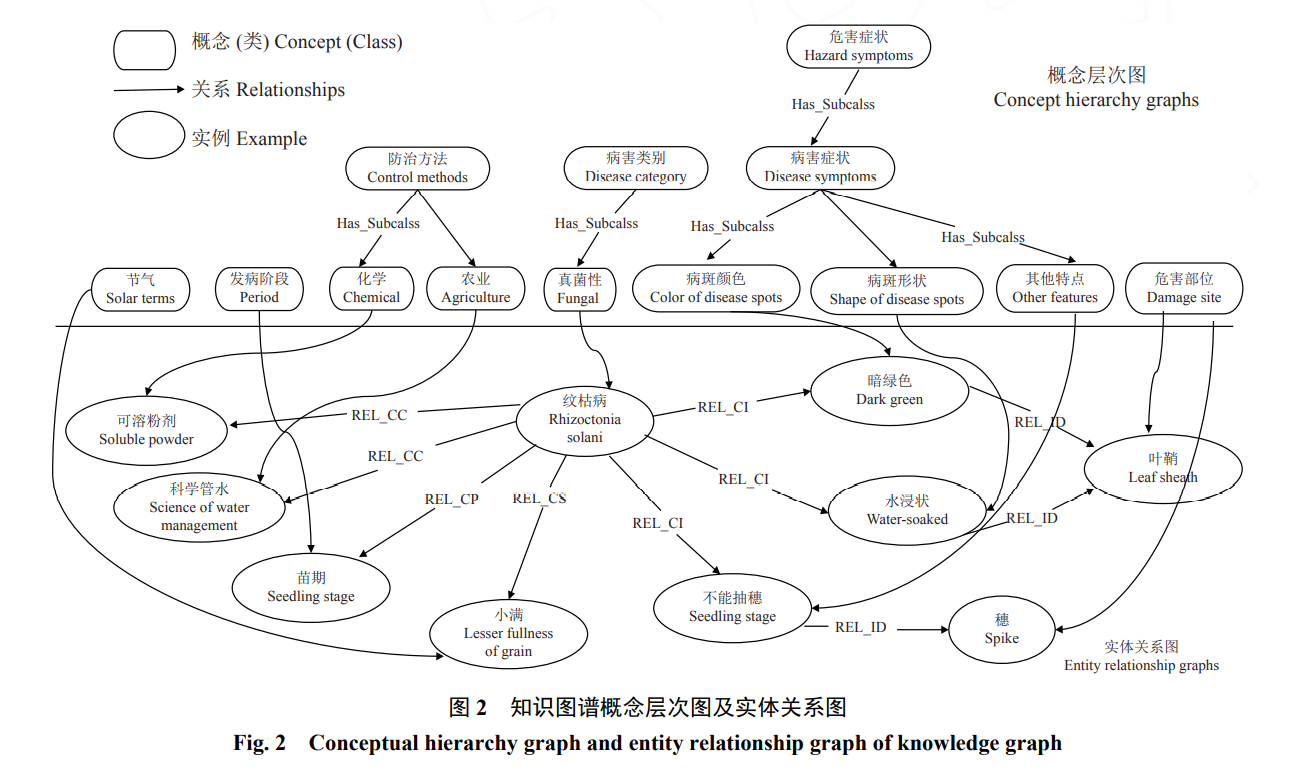
基于知识图谱的水稻病虫害智能诊断系统[1],该论文根据水稻病虫害数据,提出一种面向该领域的知识图谱构建方法,并提出确定性因子模型和知识图谱结合的知识推理方法实现了定量和定性的结合,增加了诊断的准确性和可解释性。根据需求调整加入了关联检索算法及查找功能以及Echart的可视化界面,有利于用户挖掘隐藏在图谱中的实体及关系,通过引入节气实体实现水稻病虫害的预警。另外考虑到该系统解决的是农业领域的问题,所以又加入了命名实体模型进一步提高了系统对于水稻病虫害领域数据检索、预警与诊断中知识的复杂性及不确定性的问题的准确识别率。
知识图谱在解决确定性推理问题时可以形象地通过图示来表示知识及知识之间的关系,并且易于进行知识拓展和确定性推理,方便的出推理结果。但是,知识图谱建立和维护需要专业的知识专家来负责,并且知识图谱具有有限的表达能力,无法对复杂知识进行表示,并且其在推理时相对效率较差。
知识图谱通常用于以下领域:智能客服:知识图谱可以用于支持智能客服系统,帮助客服人员快速回答用户的问题;生物信息学:知识图谱可以用于生物信息学领域,帮助研究人员组织和管理生物学相关的知识;数据整合:知识图谱可以用于数据整合,帮助组织将来自不同来源的数据整合到一起。
1.3 不确定性推理
什么是不确定性推理?其主要特点是什么?
不确定性推理是指从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。
不确定性推理具有以下特点:
- 不确定性推理以不确定的条件和规则为基础,并以概率的方式进行推理。
- 不确定性推理的结果不唯一,在相同的条件和规则下,不确定性推理可能产生多种不同的结果。
- 不确定性推理是一种概率推理,它能够帮助我们在不确定的环境中做出决策,并为我们提供可能的结果。
- 不确定性推理通常用于贝叶斯网络、推理机器人等应用中,能够帮助我们在不确定的环境中做出合理的决策。
**介绍一种不确定性推理方法及其在实际问题中的应用(要求:参考文献年份为2017-2022年),并对该推理方法的优缺点及适用领域进行分析。 **
基于改进主观贝叶斯方法识别电熔镁炉异常工况[2],深度学习前提是传感器充足且数据准确,但由于现场条件恶劣并整个熔炼过程伴随着很多不确定的信息,因此深度学习方法并不实用,本文提出一种基于改进主观贝叶斯的电熔镁炉熔炼过程异常工况识别方法,克服了传统主观贝叶斯方法中参数取值范围过大、难以确定的问题,更具实用性。同时,使用模糊隶属度函数对观察和证据进行匹配,有效解决了熔炼过程中信息 的不确定性问题,提高了异常工况识别的准确率。
主观贝叶斯方法在进行不确定性推理的优点在于它可以可以通过使用个人直觉和经验来表示不确定性,因此它特别适用于数据缺乏或不可使用的场景,在人类知识基础上进行进一步的训练,可以在新的数据到达时更新模型。但是由于其过分的依赖个人的直觉和经验,因此不可避免的与基本事实之间存在偏差,当假设不正确的时候势必会导致结果的不正确。
改进的主观贝叶斯方法通常用于以下处理不确定性的领域:在经济学中预测股票价格或汇率变化;在医学中用于分析医学数据,预测疾病发生率或患者治愈率;在营销中分析市场调研数据,并预测产品销售情况;在环境科学中用于分析环境数据,并预测气候变化或环境污染的影响。
2. 搜索与问题求解
2.1 搜索与问题求解
什么是搜索?经典的无(有)信息搜索与超越经典搜索方法的主要区别是什么?
搜索是指在一定的搜索空间以及各种约束中,按照一定的搜索策略,逐步探索并尽可能快的得到有效或者最优解的过程。
经典的无信息搜索是指在搜索过程中,搜索者不具备任何关于搜索空间的信息。
经典的有信息搜索是指在搜索过程中,搜索者具备一定的关于搜索空间的信息。
超越经典搜索方法是指在搜索过程中,搜索者具备一些超出经典搜索的更高级的信息。超越经典搜索方法可以分为两类:一类是基于知识的搜索方法,如在搜索过程中使用概念、规则等高级知识;另一类是基于机器学习的搜索方法,如通过机器学习算法优化搜索策略。
下面表是无(有)信息搜索与超越经典搜索方法的比较。
| 搜索方法 | 主要特点 | 应用领域 |
|---|---|---|
| 经典的无信息搜索 | 在搜索过程中,搜索者不具备任何关于搜索空间的信息。 | 逐步搜索、广搜、爬山搜索 |
| 经典的有信息搜索 | 在搜索过程中,搜索者具备一定的关于搜索空间的信息。 | 最短路径搜索、A*搜索等 |
| 基于知识的搜索方法 | 在搜索过程中,搜索者具备一些超出经典搜索的高级知识。 | 本体论搜索、知识图谱搜索等 |
| 基于机器学习的搜索方法 | 在搜索过程中,搜索者通过机器学习优化搜索策略。 | 机器学习搜索、深度学习搜索等 |
2.2 遗传算法及其改进方法在八皇后问题中的对比分析
什么是遗传算法?介绍3种遗传算法的改进方法,并用这些方法解决八皇后问题,设计实验方案并介绍实验开展方法,给出实验结果,基于实验结果分析各个方法的特点与优缺点(要求给出遗传算法改进方法的参考文献)
遗传算法是一种用于解决多变量、非线性、约束优化问题的机器学习方法,它借鉴了生物进化的思想来搜索最优解。遗传算法以较高的概率在搜索过程中寻找到最优的解,并能够适应性地调整搜索策略。
下面介绍3种遗传算法的改进方法:
精英保留策略[3] [4]:在遗传算法的迭代过程中,保留一定数量的最优解,以防止最优解被遗忘。在解决八皇后问题时,可以保留每一代中最优的几个棋盘布局,并将它们加入下一代的种群中。
多种群策略[5] [6]:在遗传遗传算法的迭代过程中,将种群分成多个子种群,每个子种群分别独立进行遗传操作。在解决八皇后问题时,可以将棋盘布局分成多个子集,每个子集分别进行遗传操作。这种方法可以提高算法的收敛速度,并且可以有效避免局部最优解的陷阱。
变异操作[7] [8]:在遗传算法的迭代过程中,随机选择一些棋盘布局并对它们进行变异操作。在解决八皇后问题时,可以随机选择一些棋盘布局,并在其中随机交换两个皇后的位置。这种方法可以帮助遗传算法摆脱局部最优解的陷阱,并使算法更快地收敛到全局最优解。
以初始棋盘布局作为种群的初始状态,并设置遗传算法的参数,包括交叉概率、变异概率、迭代次数等。使用精英保留策略、多种群策略、变异操作三种改进方法分别解决问题,经过选择、交叉、变异操作生成新的种群,如此更新种群直到满足终止条件,记录每种方法解决问题的效率,包括所用时间、迭代次数等。
下面是设计的实验方案, 分别比较精英保留策略、多种群策略和变异操作的效果。
- 实验一:精英保留策略,保留种群中最优解,并对其进行交叉和变异操作,得到新的解。
- 实验二:多种群策略,将种群分成多个子群,并在每个子群内进行交叉和变异操作,比较不同的子群数量的效果。
- 实验三:变异操作,比较不同的变异操作对种群的影响。
下面表给出三种遗传改进算法实验结果。
| 实验名称 | 运行时间(s) | **迭代次数(次) ** |
|---|---|---|
| Baseline | 0.558687210083007s | 28 |
| 精英保留策略 | 0.4127521514892578s | 20 |
| 多种群策略: 子群数量为2 | 0.4711589813232422s | 25 |
| 多种群策略: 子群数量为4 | 0.5764312362670898s | 30 |
| 变异操作A:随机选择两个位置进行交换 | 0.44896745681762695s | 22 |
| 变异操作B:随机选择一个位置,将其取反 | 0.5884346961975098s | 30 |
| 变异操作C:随机选择一个位置,将其赋值为0或1 | 0.544522762298584s | 27 |
通过实验,我们发现使用精英保留策略能够在最短的时间内得到较优解,并且迭代次数较少; 在多种群策略的实验中,随着子群数量的增加,算法的执行时间和迭代次数都会增加; 在变异操作的实验中,不同的变异操作对种群的影响不同,有的变异操作能够得到较优解,有的则不能。相比于传统的遗传算法,这些改进方法能够显著提高算法的效率和稳定性。
基于实验结果分析各个方法的特点与优缺点:
- 精英保留策略的优点在于能够保证最优解的稳定性,使得算法不易陷入局部最优解的陷阱。缺点在于,它可能会导致算法收敛速度减慢,因为种群中的个体更加相似,难以达到多样性,可能无法收敛到最优解;
- 多种群策略的优点在于能够增加种群的多样性,它能够有效提高算法的收敛速度,并且能有效避免局部最优解的陷阱。缺点在于,它会增加算法的计算复杂度,因为需要对种群进行分组并进行多次遗传操作;
- 变异操作的优点在于,它能够有效帮助算法摆脱局部最优解的陷阱,使得算法能够更快地收敛到全局最优解。缺点在于,如果变异概率过高,则可能会导致算法的稳定性下降,因为变异操作会使算法走向更劣的方向。
3. 机器学习基本理论与方法
3.1 机器学习的基本概念及其学习策略
机器学习的要素、基本学习策略
机器学习是人工智能的一个分支,它通过对数据进行分析和模型训练,使计算机能够从数据中学习规律,旨在建立具体领域的学习算法与学习系统,并在以后的应用中自动进行决策和预测。
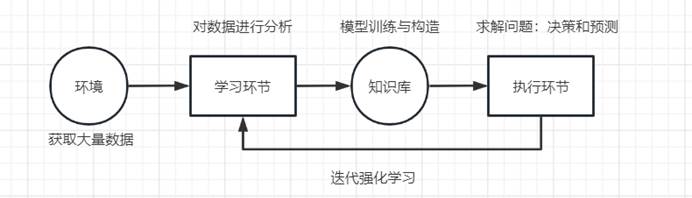
- 机器学习的基本要素包括数据集、目标函数和学习算法。
- 数据集是机器学习的基础,特征是描述数据点的信息,而标签是我们想要预测或预测的目标。
- 目标函数是用来衡量机器学习系统对学习目标的达成情况的函数,通常都是用来衡量学习系统的预测结果与真实结果的差距。
- 学习算法是机器学习的核心,它是用来帮助机器学习系统找到最优模型的算法。
基本的学习策略包括:记忆学习,传授学习,类比学习,归纳学习和解释学习。
- 记忆学习: 通过记住大量信息来学习,通常用于对训练样本进行记忆,以便在需要时快速调用。
- 传授学习: 通过人为讲解或教导来学习,常常体现为数据预处理和特征工程,即通过人为设计的特征来帮助模型学习。
- 类比学习: 通过将新的情况与已知的情况进行比较来学习,通过调整模型的参数来学习训练样本的规律。
- 归纳学习: 通过总结已知的情况来推断新的结论或规律,常常体现为对模型的泛化能力进行评估,即模型对未知数据的预测能力。
- 解释学习: 通过对新的情况进行分析和理解来达到学习的目的,解释学习可以通过可解释模型、特征选择和模型解释技术实现,使得模型的决策过程可解释,从而帮助我们了解模型的决策过程,以便于对模型进行进一步的优化。
3.2 人工神经网络及其应用
3.2.1 人工神经网络的结构设计
介绍人工神经网络的结构类型,以卷积神经网络、循环神经网络、玻尔兹曼机等为例,介绍不同结构神经网络的特点及其应用领域。
常见的人工神经网络结构类型包括:
- 前馈神经网络(Feedforward Neural Network)是最常见的人工神经网络结构,由输入层、隐藏层和输出层组成。
- 卷积神经网络(Convolutional Neural Network, CNN)是一种具有卷积层的人工神经网络,卷积层能够提取图像的特征,通常用于图像识别任务。
- 循环神经网络(Recurrent Neural Network, RNN)是一种具有循环层的人工神经网络,通常用于处理序列数据,如语音识别、文本分析等序列任务。
- 玻尔兹曼机(Boltzmann machine)是一种具有自编码层的人工神经网络,能够自动学习数据的结构,通常用于无监督学习任务。
下面表是不同结构神经网络的特点及其应用领域比较。
| 结构类型 | 卷积神经网络 | 循环神经网络 | 玻尔兹曼机 |
|---|---|---|---|
| 特点 | 卷积层:卷积层能够提取图像的特征 池化层:池化层能够降低数据的维度 |
循环层:能够记录序列数据的历史信息 | 自编码层:能够自动学习数据的结构 |
| 应用领域 | 图像识别 | 语音识别、序列分析 | 无监督学习 |
| 优点 | 能够提取图像特征 | 能够记录序列数据的历史信息 | 能够自动学习数据结构 |
| 缺点 | 速度较慢 | 实现较复杂 | 需要大量的训练数据 |
| 变体 | 卷积神经网络(CNN)、深度卷积神经网络(DCNN)、残差卷积神经网络(ResCNN) | 循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU) | 玻尔兹曼机(BM)、受限玻尔兹曼机(RBM) |
3.2.2 人工神经网络的学习算法
介绍目前常用的人工神经网络的学习算法(根据参考文献进行介绍)
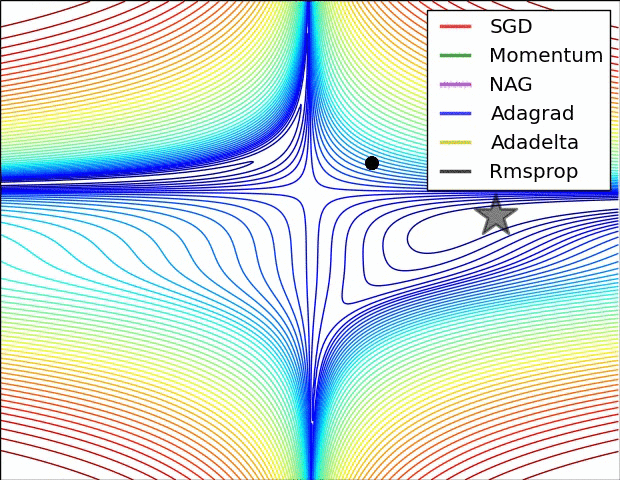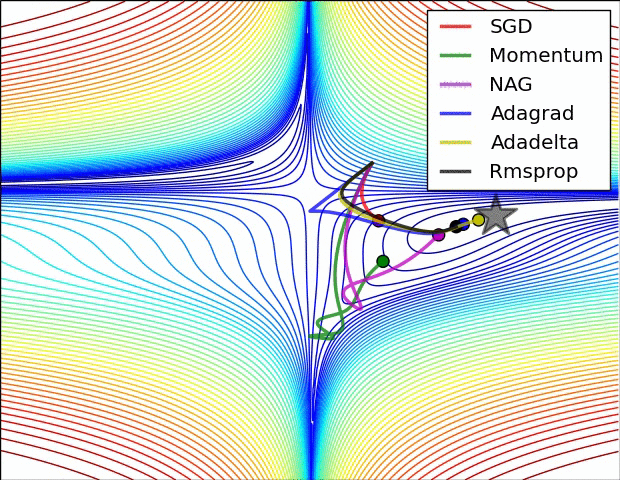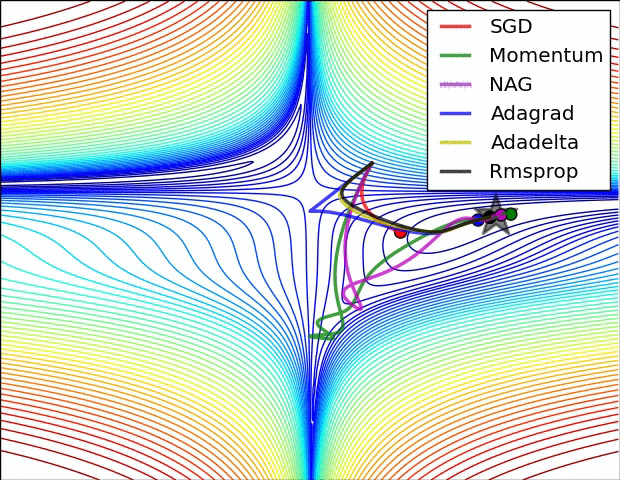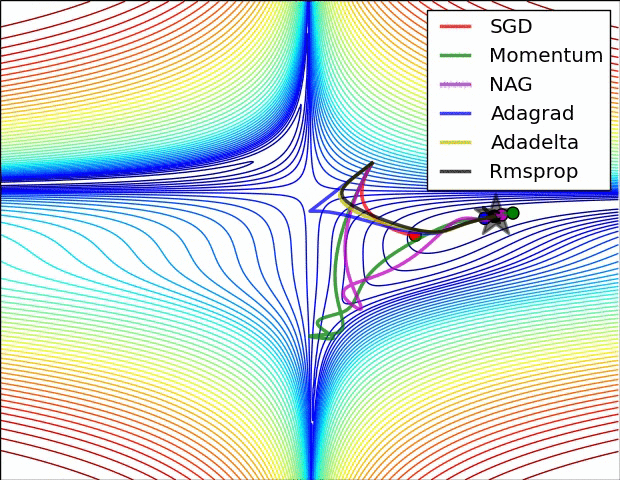
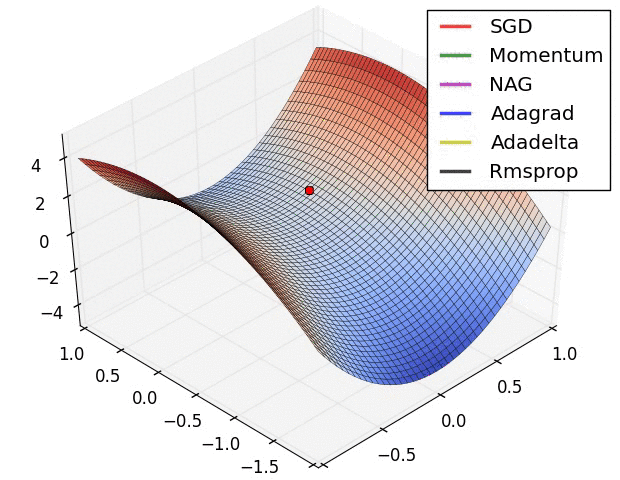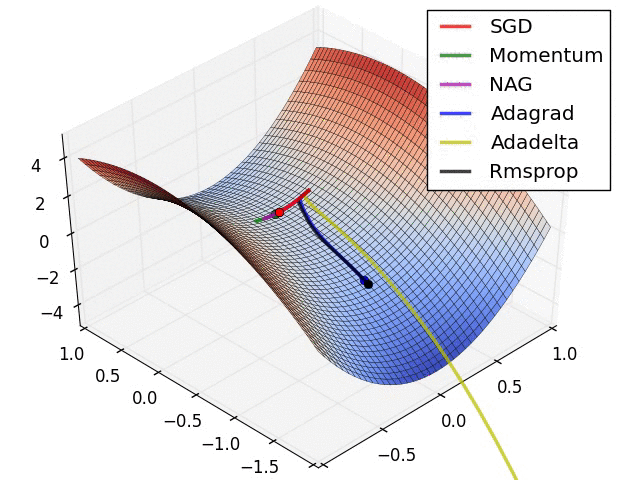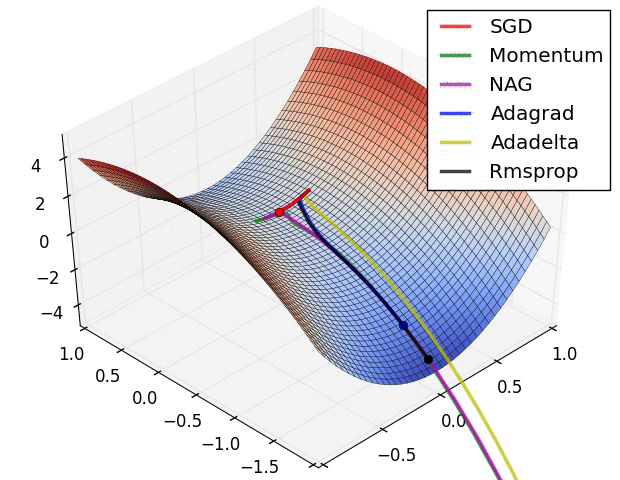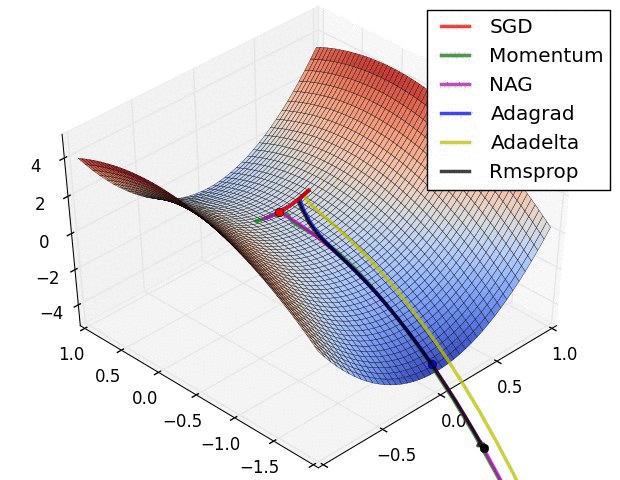
常用的人工神经网络的学习算法包括随机梯度下降法、动量法以及自适应动量法[9]。
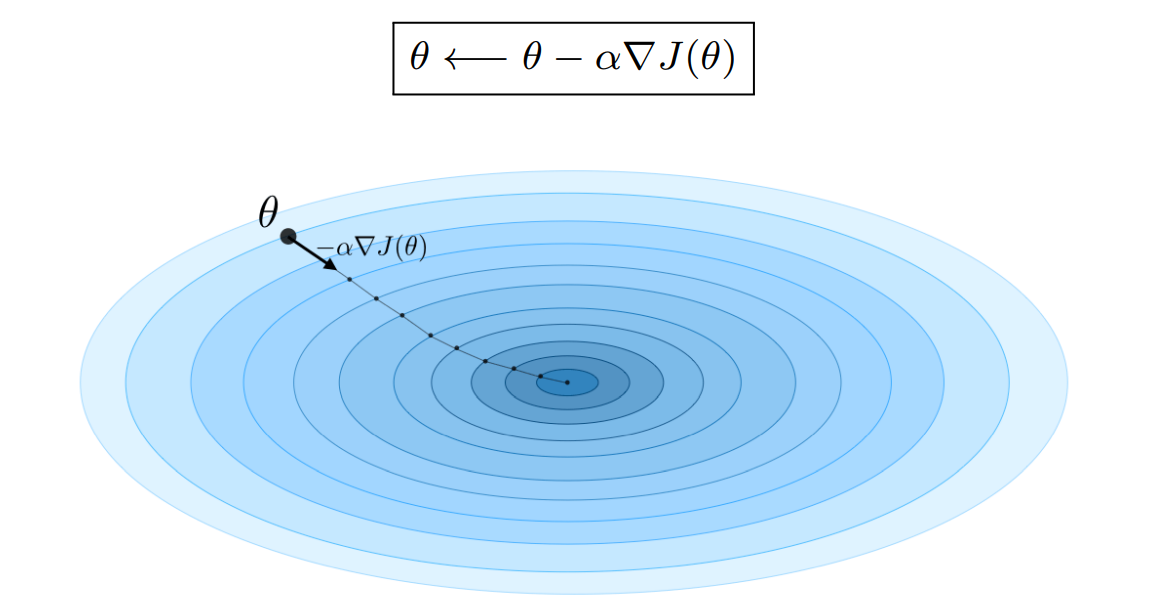
随机梯度下降法[10](Stochastic Gradient Descent,SGD)是一种基于梯度下降算法的变体,用于解决凸优化问题。SGD是一种经典的优化器,用于优化模型的参数。SGD的基本思想是,通过梯度下降的方法,不断调整模型的参数,使模型的损失函数最小化。SGD的优点是实现简单、效率高,缺点是收敛速度慢、容易陷入局部最小值。
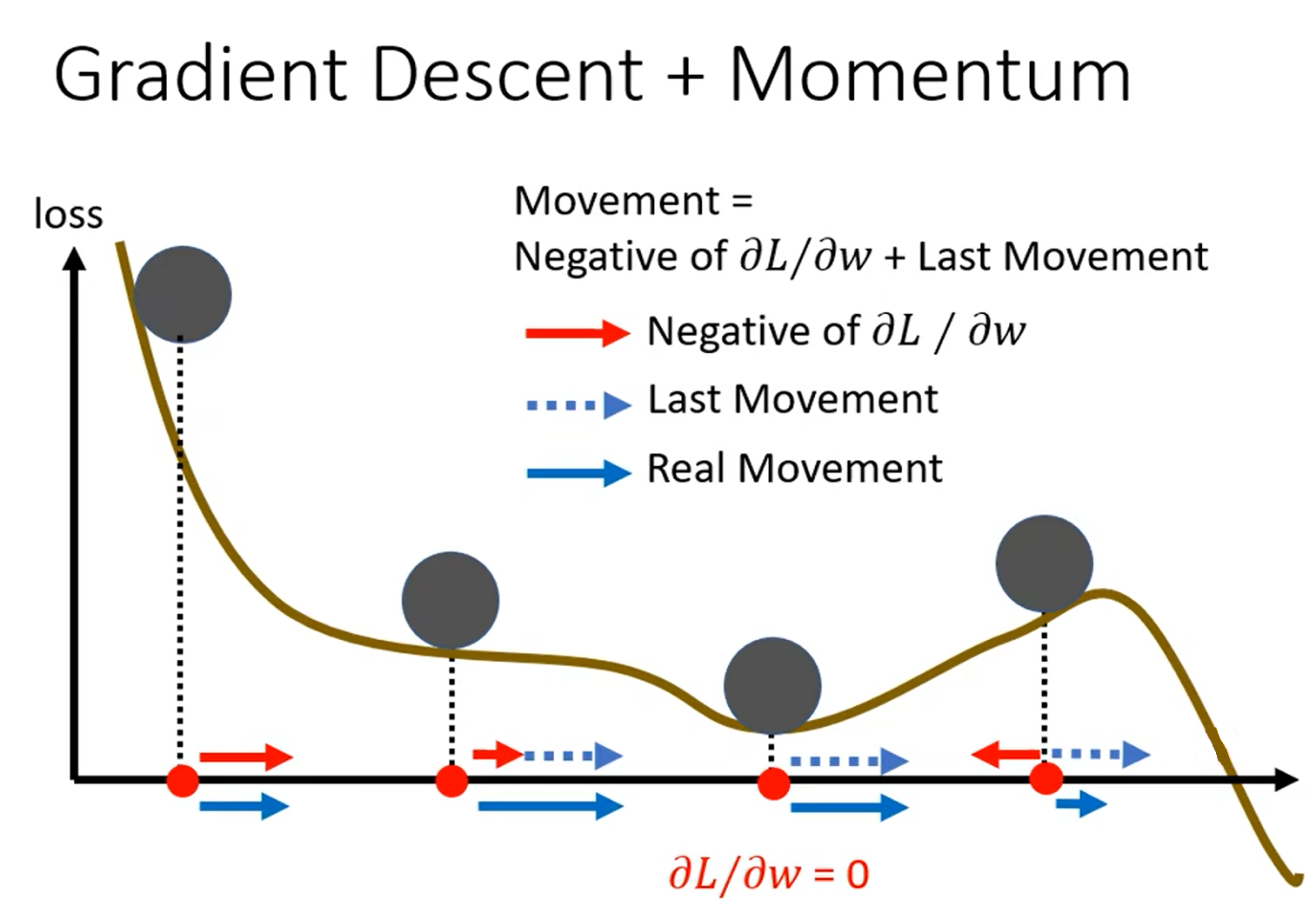
动量法[11] [12](Momentum)是一种用于优化梯度下降更新的方法,它通过使用一个动量项来提升梯度下降法的收敛速度。动量项是一个以梯度为参数的指数移动平均值,可以帮助模型快速收敛到最优解。通过论文实验结果发现,使用动量法能够显著提升模型的训练速度,并且可以有效避免模型陷入局部最优解。
自适应动量法[13](Adaptive Gradient Algorithm,Adam)是一种基于自适应学习率的优化算法,用于训练人工神经网络和其他机器学习模型。Adam结合了随机梯度下降(SGD)和动量法的思想,通过自适应调整学习率来提高训练效率。Adam是一种近似于随机梯度下降的优化器,用于优化模型的参数。Adam的基本思想是,通过维护模型的梯度和梯度平方的一阶动量和二阶动量,来调整模型的参数。Adam的优点是计算效率高,收敛速度快,缺点是需要调整超参数。
3.2.3 人工神经网络在语音识别方面的应用
以某一实际问题为例,说明采用神经网络方法解决该问题的基本方法,发展现状。(根据参考文献进行介绍)
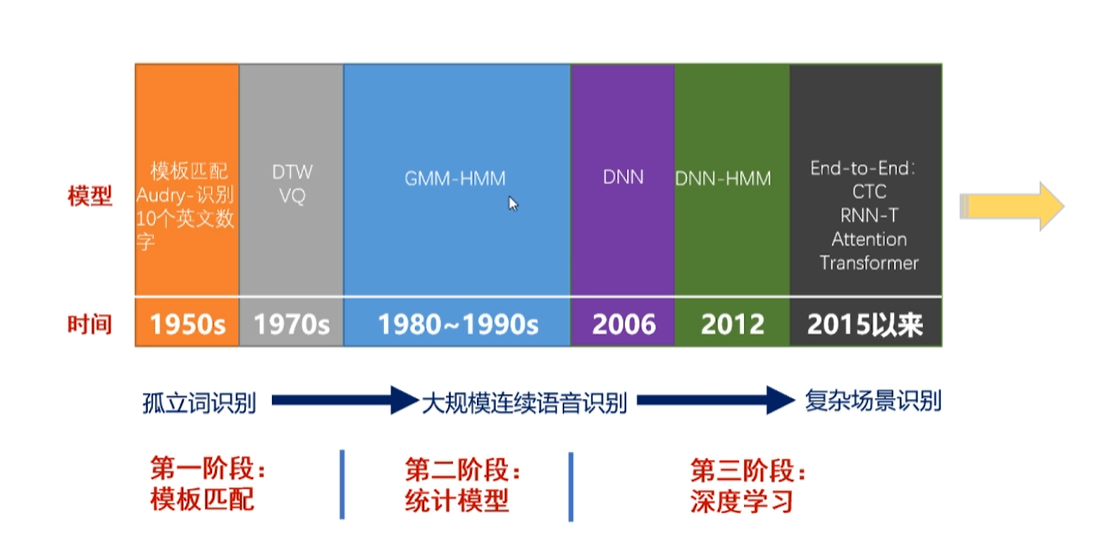
语音识别的发展历史可以追溯到贝尔实验室提出的基于模板匹配(DTW)的孤立词识别,再到第二阶段基于统计模型(GMM-HMM)的语音模型,直到第三阶段HMM也一直在与DNN结合应用,不过现在的研究也逐渐抛弃掉了HMM这种传统方法,基于神经网络的端到端模型(E2E)逐渐成为当下主流方法,并实现了各种数据集的SOTA。尽管基于CTC、RNN-T、Attention、Transformer等神经网络的E2E语音识别的论文层出不穷,但是其由于稳定性、神经网络的不可解释带来的安全性挑战和实际落地困难等原因,在工业界还没有得到覆盖应用[14]。
语音识别的任务为,找到对应观察序列𝑂的概率最高的词序列𝑊 。 按贝叶斯准则可以写为以下公式:
$$
\widehat{W}=\arg \max _W P(W \mid O)=\operatorname{argmax} \frac{P(O \mid W) P(W)}{P(O)}
$$
$$
\widehat{W}=\arg \max _W P(O \mid W) P(W)
$$
要找到最可能的词序列,必须使上式右侧两项的乘积最大。其中第 一项由声学模型决定,第二项由语言模型决定。
下面展示的是传统的基于GMM-HMM的语音识别过程:
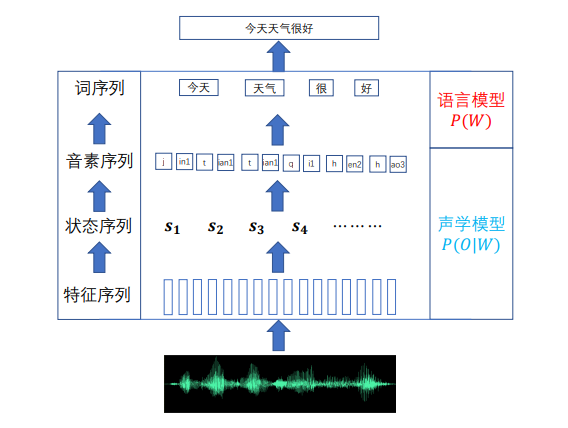
其建模过程就是一个识别的反过程,首先通过分词模块将句子分为较小的单位,进而词典将词分为音素(声母韵母),由于人的发音包含双重随机性(中间每一个发音的持续时长不一样),然后需要通过隐马尔可夫模型为其发音的不确定因素建模。
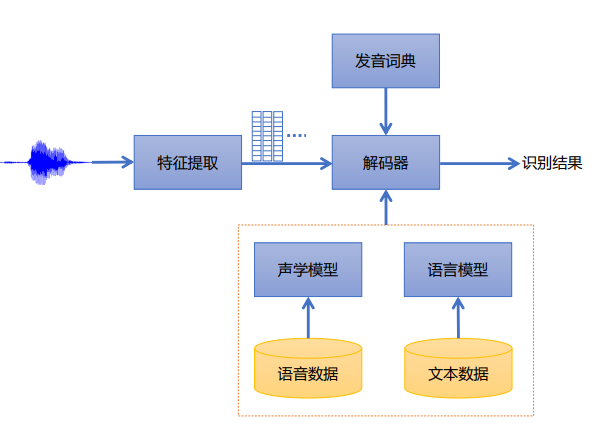
前面介绍的是建模和识别过程,也就是所谓的编码和解码过程,但实际在使用的时候会把多个设计的模块整合在一起,也就是基于DNN-HMM的hybrid架构,其中就包括发音词典、声学模型、语言模型和特征提取模块,最后将这些模块整合在解码器上形成一个静态网络,解码器是基于加权有限状态机(WFST),是当下工业界使用最广泛的。但是当下语音识别由于一些鸡尾酒会复杂场景、口语化、语种混杂以及一些语言本来就非常小众的低资源数据等原因,语音识别仍然面临着很多的挑战[13]。
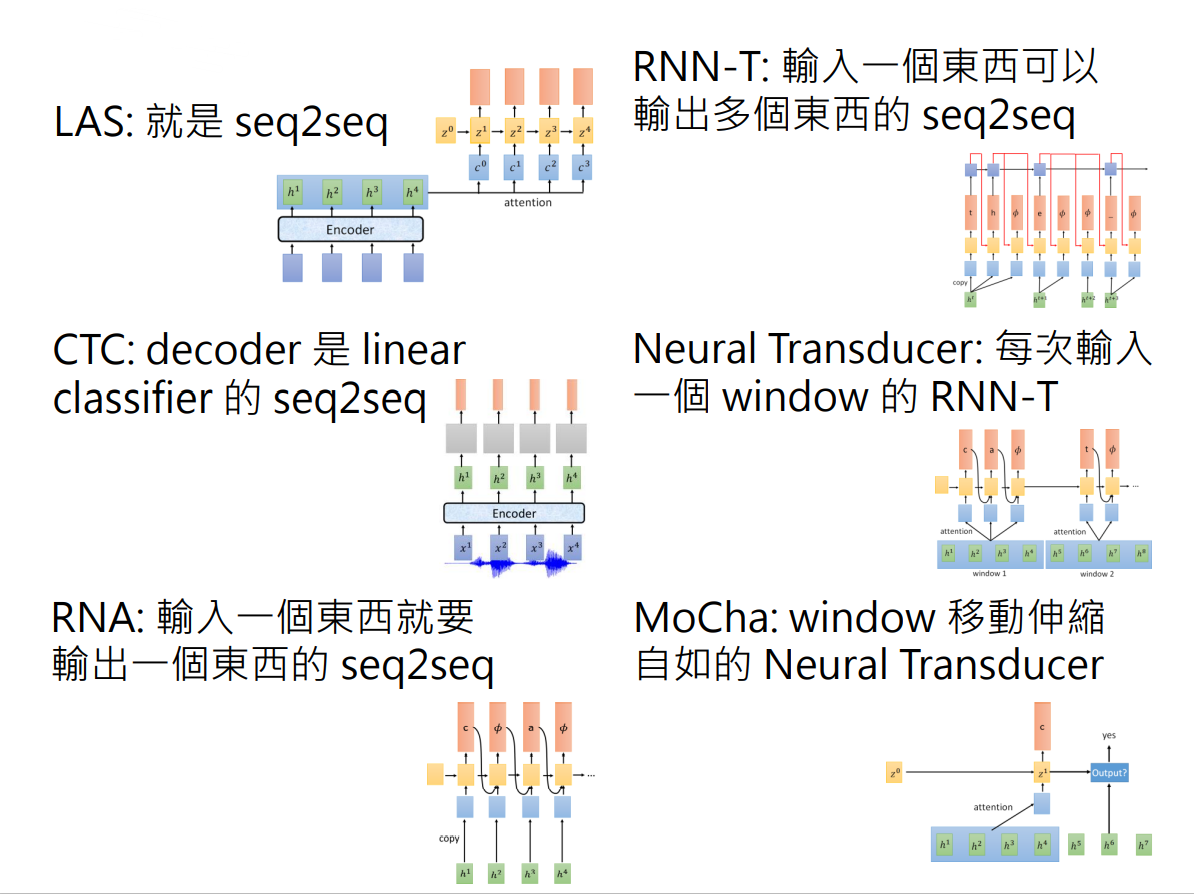
下面介绍几种当下在神经网络的应用下用来做端到端语音识别任务的模型架构[15],分别是LAS(Listen Attention and Spell)、CTC(Connectionist Temporal Classification)、RNA(Recurrent Neural Aligner)、RNN-T(RNN Transducer)、NT(Neural Transducer)以及MoChA(Monotonic Chunkwise Attention)。
- LAS是一个典型的使用attention机制的seq2sqe的模型,其中Listen的部分是一个encoder,使用RNN、CNN或者TDNN(Time-delay DNN)对输入声学特征提取高维特征;Spell部分是一个decoder,其作用就是输出概率最大的token。
- CTC只需要encoder将输入的特征提取高维特征,而后通过一个Classifier进行输出,这就导致输入T个声学特征它要输出T个token。但是CTC最关键的是它可以输出 ɛ 并且可以合并重复的字符,这样就解决了seq2seq中一般不等长的问题。
- RNA本质是就是在CTC Linear Classifier的基础上将decoder改成了RNN结构,每一次在输出token的时候不只是接受声学特征还会接受上一次产生的token,这样就省略掉了重复字符的合并问题。
- RNN-T则是对RNA的改进,因为有可能一个发音特征对应的输出有可能会对应多个token并以 ɛ 结束声学特征的解码,eg:”th”的发音。
- NT的思想是不像前面四个模型每次都只读入一个声学特征,而是每次读入多个声学特征并使用Attention机制;在解码的时候同RNN-T的输出策略一样,是会输出多个token的并以 ɛ 结束本块输入的解码。
- MoChA的思想和NT比较相似,不过NT中Attention的块读入的声学特征大小是固定的,而MoChA可以动态地调整读入大小。
4. 总结
对论文主要内容进行总结,并给出相关结论。
人工智能是一门研究计算机如何实现智能的学科。它的研究目标是使计算机具有人类的智能行为,包括自然语言理解、图像识别、决策制定等能力。在人工智能的发展历程中,出现了许多不同的算法和方法,其中包括从简单的知识表示与推理到复杂的机器学习、遗传算法、神经网络等。
从20世纪50年代起人工智能这门学科的正式成立,到当下由于神经网络引发的新一代人工智能的兴起,人们正雄心勃勃,对人工智能抱着非常乐观的态度。但同时我们也应该保持警惕,最初的人工智能博弈证明定理的时候,人类就曾相信在十年左右就会出现人类思考级别的人工智能。但是因为人类认为机器中绝对的0和1所代表的冰冷的逻辑并不能实现细致入微的生物大脑般的思维过程,人工智能产业也曾一度受到质疑和打击。受到仿生智能计算的驱动产生的神经网络以及Hinton教授等人在神经网络前途渺茫时坚持的决心使得人工智能又一次地完成了破冰,启动了新一轮深度学习引领的人工智能的黄金时代。
![图13 “犯错误”的人工智能[16]](https://picture-store-repository.oss-cn-hangzhou.aliyuncs.com/blog/202301122003613.jpg)
人工智能在许多领域都有广泛应用,如自然语言处理、计算机视觉、推荐系统等。它的应用可以提高工作效率,并为解决复杂问题提供新的思路。但是尽管深度学习引发的人工智能浪潮表现出优越的性能,但是由于神经网络的深度和宽度的不断扩大,模型在规模上越来越大,神经网络越来越像一个深不可测的黑盒子[17]。正是由于神经网络缺乏可解释性,由于安全性其在医疗、智慧生活等领域的全面应用还有待商榷。为此,我们需要探索可解释AI的技术,如可解释神经网络、黑箱可解释性和模型解释性。这些技术能帮助我们更好地理解人工智能的决策过程,并为模型的设计和应用提供指导。知其然,也知其所以然。
5. 参考文献
- .于合龙,沈金梦,毕春光,梁婕,陈慧灵.基于知识图谱的水稻病虫害智能诊断系统[J].华南农业大学学报,2021,42(05):105-116. ↩
- .袁杰,王姝,王福利,孙晓辉.基于改进主观贝叶斯方法识别电熔镁炉异常工况[J].东北大学学报(自然科学版),2021,42(02):153-159. ↩
- .Liao, H.-S., & Wu, Y.-C. (2002). A new genetic algorithm using elitism for numerical optimization. 《Journal of Chinese Institute of Engineers》, 25(4), 627-632. ↩
- .Wu, Y.-C., and Liao, H.-S. 2004. “A Study of Elitism in Genetic Algorithms.” 《Journal of Chinese Institute of Engineers》 27 (2): 209-216. ↩
- .Coello, C. A. C. 2002. “Multi-population Genetic Algorithms for Multimodal Optimization.” 《IEEE Transactions on Evolutionary Computation》 6 (3): 282-295. ↩
- .Coello, C. A. C. 2004. “A Comparative Study of Multi-Population Genetic Algorithms for Multimodal Optimization.” 《IEEE Transactions on Evolutionary Computation》 8 (3): 256-279. ↩
- .Fogel, D. B. 1994. “The Role of Mutation in Genetic Algorithms: A Review.” 《IEEE Transactions on Evolutionary Computation》 1 (1): 3-17. ↩
- .Fogel, D. B. 1996. “A Survey of Mutation Operators for Genetic Algorithms.” 《IEEE Transactions on Evolutionary Computation》 1 (2): 125-142. ↩
- .Sebastian Ruder. “An overview of gradient descent optimization algorithms” arXiv: Learning(2016): n. pag. ↩
- .Robbins, H. and Monro, S. (1951). A Stochastic Approximation Method. Annals of Mathematical Statistics, 22(3), 400-407. ↩
- .Ning Qian. 1999. On the momentum term in gradient descent learning algorithms. Neural Netw. 12, 1 (Jan. 1999), 145–151. ↩
- .Sutskever I , Martens J , Dahl G , et al. On the importance of initialization and momentum in deep learning[C]// International Conference on Machine Learning. JMLR.org, 2013. ↩
- .Kingma, D. P. and Ba, J. (2014). Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations (ICLR). ↩
- .洪青阳,李琳.语音识别:原理与应用[M].北京:电子工业出版社,2020.06.332. ↩
- .Dr Jinyu Li, Partner Applied Science Manager, Microsoft Title: Advancing end-to-end automatic speech recognition and beyond ↩
- .Szegedy C , Zaremba W , Sutskever I , et al. Intriguing properties of neural networks[J]. Computer Science, 2013. ↩
- .Sha Yuan et al. A Roadmap for Big Model ,2022. ↩
- .ChatGPT: Optimizing Language Models for Dialogue ↩
- .StuartJ.Russell, PeterNorvig, 诺维格,等. 人工智能:一种现代的方法[J]. 清华大学出版社, 2013. ↩