决策树-属性缺失处理
数据集中的样本通常在某些属性上是缺失的,如果属性缺失的样本数量较少,我们可以直接简单粗暴的把不完备的样本删掉。但如果有大量样本都有属性值缺失,那么就不能简单的删除了,因为这样删除了大量有用信息,模型性能会有影响。本篇博客介绍如何处理属性缺失的样本。
1.如何在属性缺失的情况下进行属性选择(比如“色泽”这个属性值缺失,那么如何计算“色泽”的信息增益)
2.给定划分属性,若样本在该属性上的值是缺失的,如何对这个样本划分(即到底把这个样本划分到哪个节点)
比较发现,“纹理”在所有属性中信息增益最大,因此纹理被选为根节点属性划分,划分结果如下: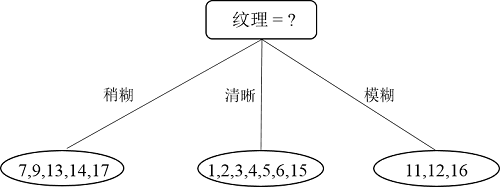
那么问题来了,编号[8 10]的样本在“纹理”属性上是缺失的,该分到哪个分支里?其实这两个样本会同时进入三个分支里,只不过进入每个分支后权重会被调整(在开始时每个样本权重都初始化为1)。编号为8的样本进入三个分支后权重调整为5/15,7/15和3/15;编号10的样本同样的操作和权重。因此,经过第一次划分后的决策树如图: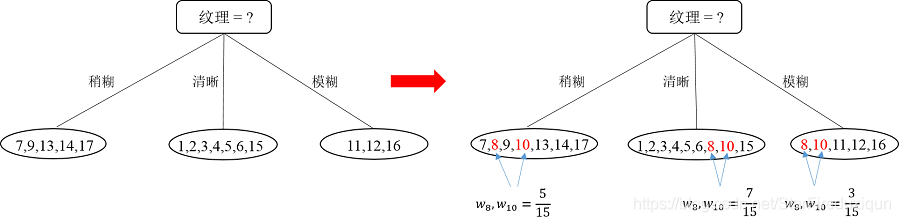
构造决策树是一个递归过程,接下来执行“纹理=稍糊”这个分支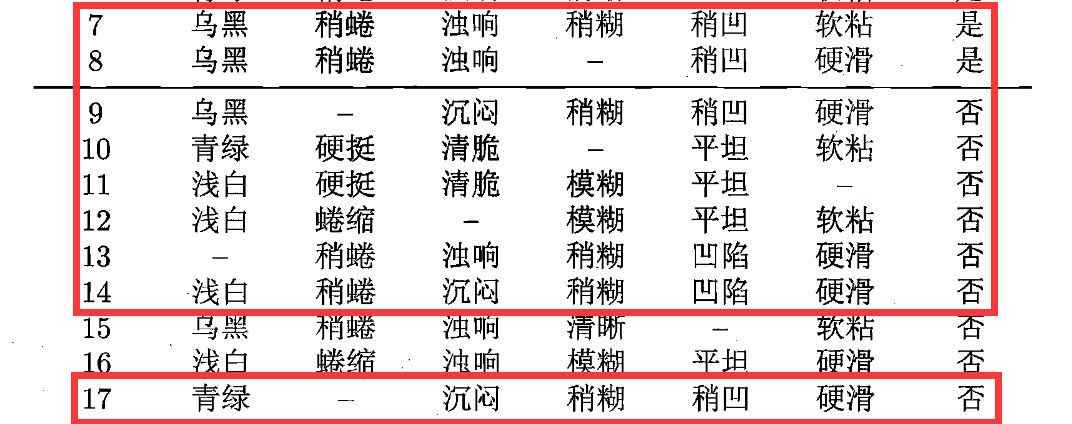
对比发现属性“敲声”的增益最大,选择敲声作为划分属性,决策树如下: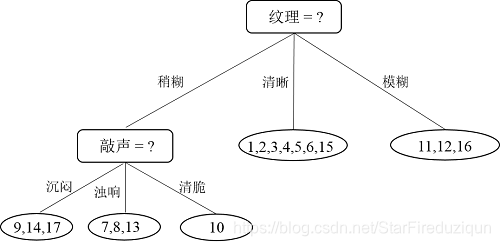
决策树-属性缺失处理
https://blog.baixf.shop/2022/10/24/Machine Learning/决策树-属性缺失处理/