Class 10 端到端语音识别
一、端到端语音识别的动机
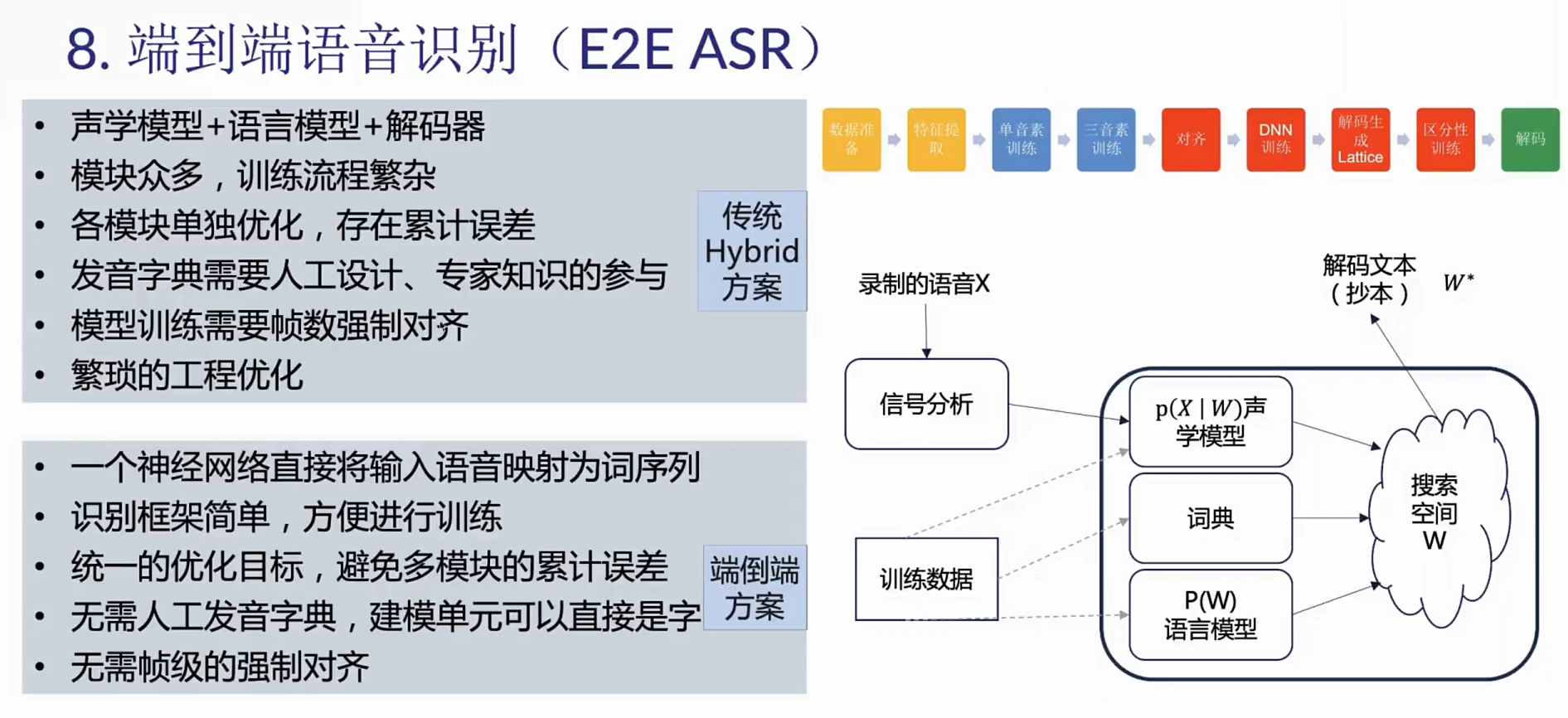
- 传统语音识别整体流程

- 传统语音识别声学模型训练
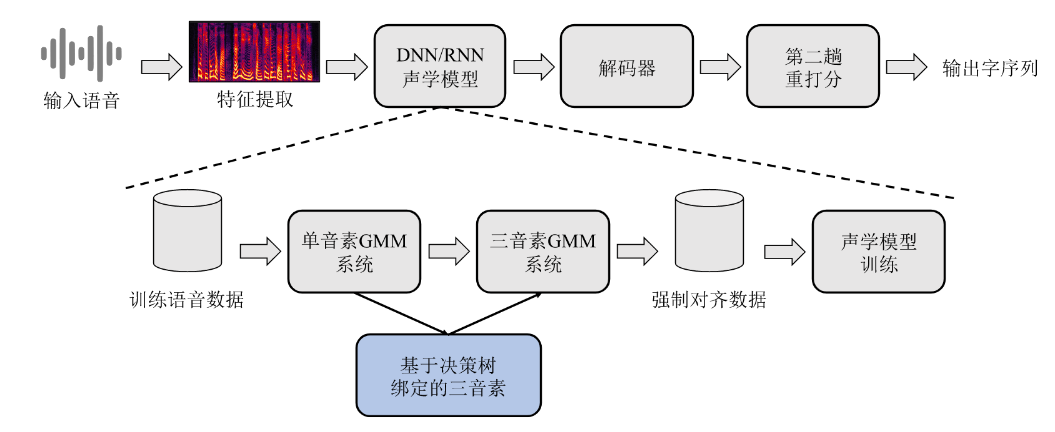
- 传统语音识别语言模型训练

- 传统语音识别缺点
- 流程非常的多而繁杂
- 入门门槛非常高
- 大多数传统语音识别系统包含声学模型、语言模型和发音模型,每个模型都分开训练
- 若使用区分性训练,上述模型翻倍
- 对特定的语言定义发音字典、音素集需要专业知识,并且非常耗时
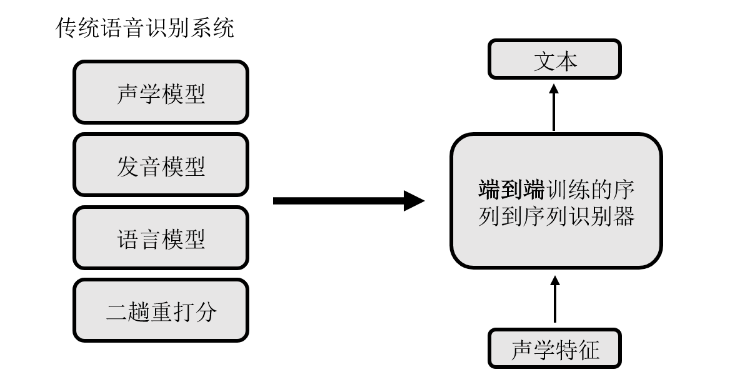
- 什么是端到端语音识别?
使用单个序列到序列模型,直接将输入声学特征序列映射到文本
二、Sequence-to-Sequence & Attention
Sequence-to-Sequence
- 什么是机器翻译?
机器翻译(Machine Translation, MT),是把一种语言(源语言)的句子 x 翻译成另一种语言 (目标语言)的句子 y 的任务

什么是神经机器翻译?
- 神经机器翻译(Neural Machine Translation, NMT),是通过单个神经网络实现机器翻译的方法
- 这种神经网络框架称作Sequence-to-Sequence (Seq2Seq) 或者encoder-decoder,其包含两个RNN
- Seq2Seq框架的优点是:输入输出不需要等长,而且两者长度不固定
- 当使用一个RNN时,输入输出一般等长
什么是Sequence-to-Sequence?
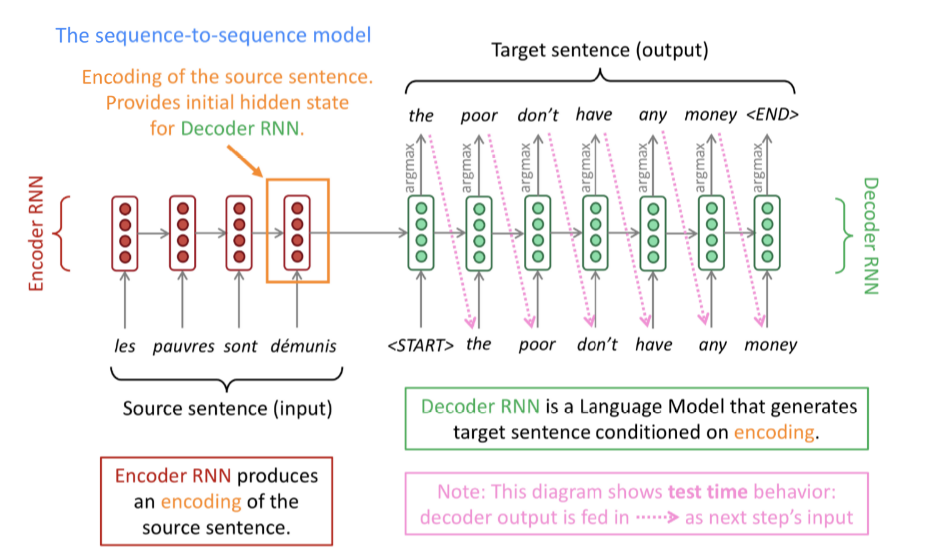
Problems : Encoding of the source sentence. This needs to capture all information about the source sentence. Information bottleneck.
Attention
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图。

在计算attention时主要分为三步:
- 第一步是将
query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等; - 第二步一般是
使用一个softmax函数对这些权重进行归一化; - 最后将
权重和相应的键值value进行加权求和得到最后的attention。
ticks:
- 目前在NLP研究中,key和value常常都是同一个,即key=value。
- Attention在NLP中其实我觉得可以看成是一种自动加权,它可以把两个你想要联系起来的不同模块,通过加权的形式进行联系。目前
主流的计算公式有以下几种:

- 它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。不过在NLP中的attention机制和人类的attention机制还是有所区别,它基本还是需要
计算所有要处理的对象,并额外用一个矩阵去存储其权重,其实增加了开销。而不是像人类一样可以忽略不想关注的部分,只去处理关注的部分。
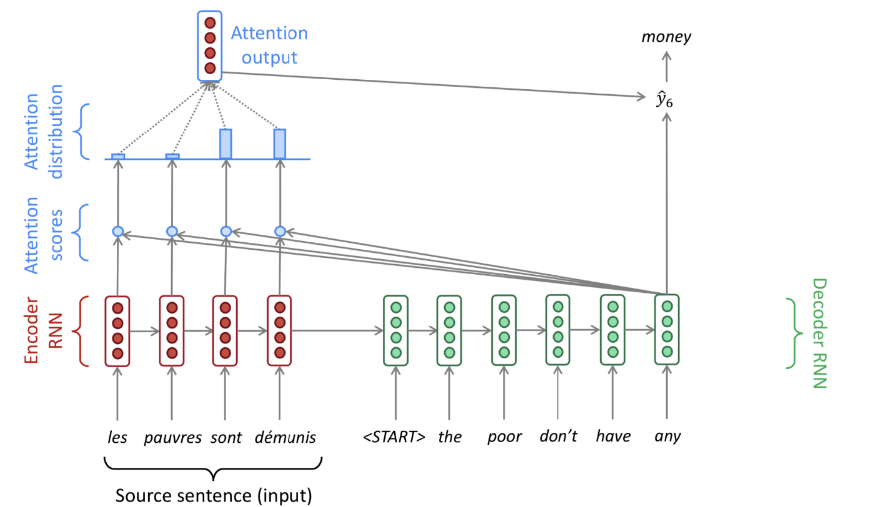
Seq2Seq with Attention
关键点:在decoder的每一步,只关注源句子的特定部分
Self-Attention
- values and query come from the same layer
- 优点:
- 能够替换RNN,对时序进行建模
- 易并行,计算快
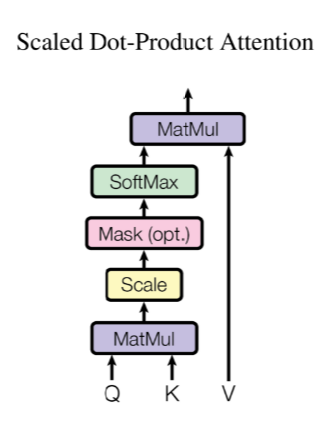
Scaled Dot-Product Attention
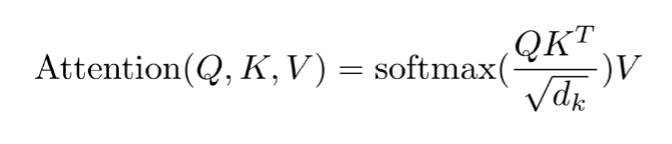
- K 和 V 一般是同一个向量或矩阵
- 当Q、K、V 是同一个向量或矩阵时,即是self-attention
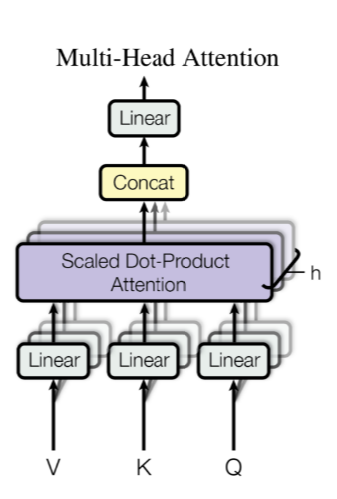
Multi-head Attention (MHA)

- K 和 V 一般是同一个向量或矩阵
- 当Q、K、V 是同一个向量或矩阵时,即是self-attention
Sequence-to-Sequence & Attention 总结
- 在Seq2Seq中,输入输出可以不等长
- Seq2Seq通过单个模型直接将输入映射成输出
- Seq2Seq单个模型一般由两个RNN组成:Encoder和Decoder
- 通过Attention机制,使得输出的每一步可以只关注部分输入
三、端到短语音识别系统
1.Listen, Attend and Spell(LAS)
LAS:把Seq2Seq的输入换成语音特征序列 X= x1, … , xT) ,输出换成文本序列Y = y1, … , yU,可直接将 X映射成 Y,从而实现了端到端语音识别。
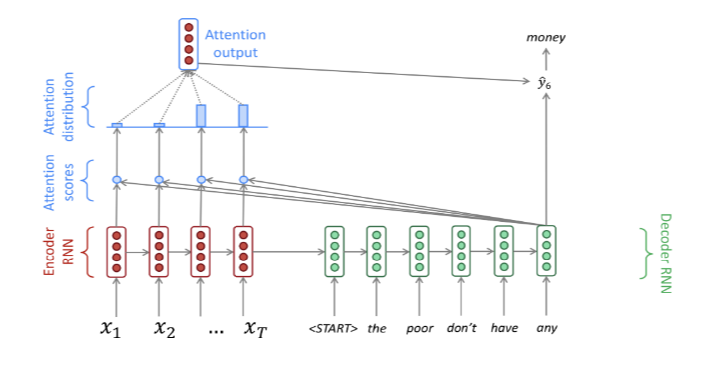
- 不同论文用的Encoder RNN、Decoder RNN、Attention有所不同,但整体框架不变。
- 其他文献中对于LAS或Seq2Seq也有不同的画法,但本质相同。
2.Speech Transformer
Transformer: A High-Level Look

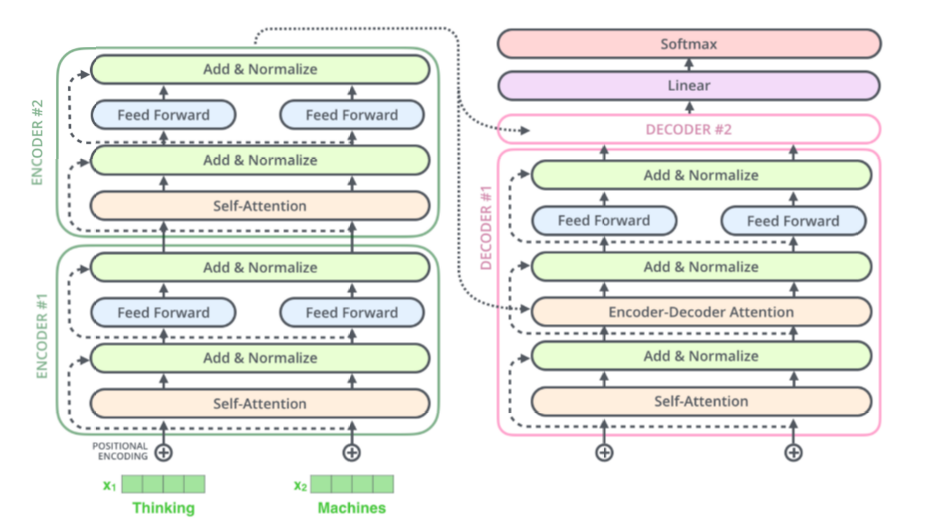

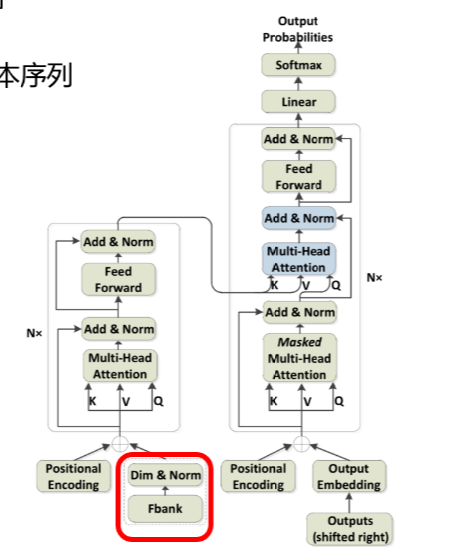
Speech Transformer
输入是语音特征序列,输出是文本序列
实现了端到端语音识别
3.CTC
给定语音特征序列 X = x1, x2,, … , xT)和文本序列 Y = y1, y2,, … , yU
在Seq2Seq框架中,通过两个RNN直接将语音特征序列 X 映射到文本序列Y
想训练单个RNN,直接将语音特征序列 X 映射到文本序列 Y
- 使用RNN时,其输出序列 Y 与输入序列 X 等长,但是文本序列 Y 一般与特征序列 X 不等长
解决方案
在输出集合中引入表示空的符号 blank(ε)
- 合并重复的字符
- 移除 ε 符号
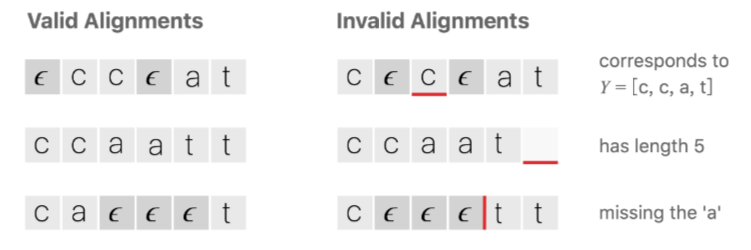
- 优点:
- 同个 Y 对应多个对齐!
- 对齐具有单调性
- 引入 ε 后,不需要预先知道特征序列 X 的对齐也可以得到输出序列
训练

每个 A 相当于一条可以得到 Y 的路径,上式相当于对多条可以得到 Y 的路径进行求和
解码

总结

外接语言模型
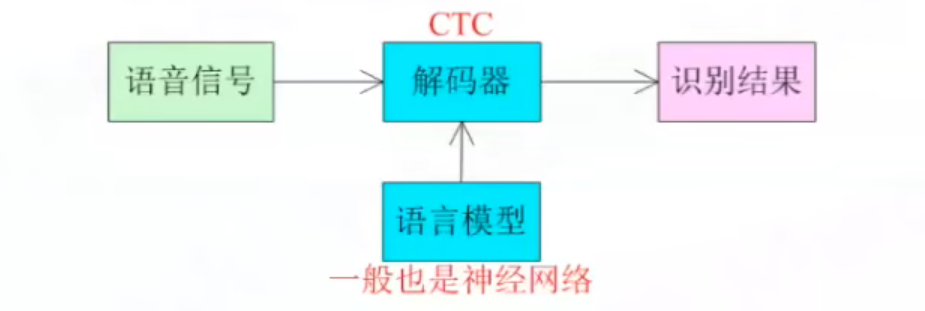
4.RNN-Transducer
本质:对 CTC 进行增强

- Encoder
- 和CTC一样,可以是任何RNN类的网络
- 将声学特征 X = x1, … , xT) 映射到隐向量 h = ℎ1, … , ℎT)
- 像声学模型一样
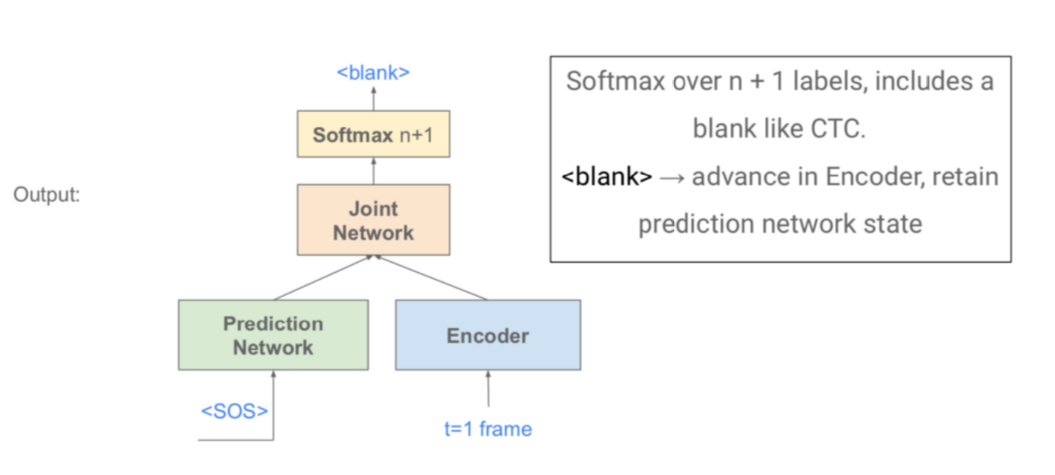
- + Prediction Network
- 对输出的依赖关系进行建模,可以是任何单向RNN类网络
- 把前一时刻的RNN-T输出y_u-1作为输入,预测下一个输出Pu
- 像语言模型一样
- + Joint Network
- 用MLP把Encoder和Prediction Network的输出结合在一起,预测最终的网络输出
- 把声学信息和语言信息集合在一起
- Softmax计算输出概率,RNN-T Loss[1][2]和CTC Loss类似,用前向后向算法进行计算
- 各部分联合在一起进行训练,是单个模型
RNN-T相比其他E2E模型的优点


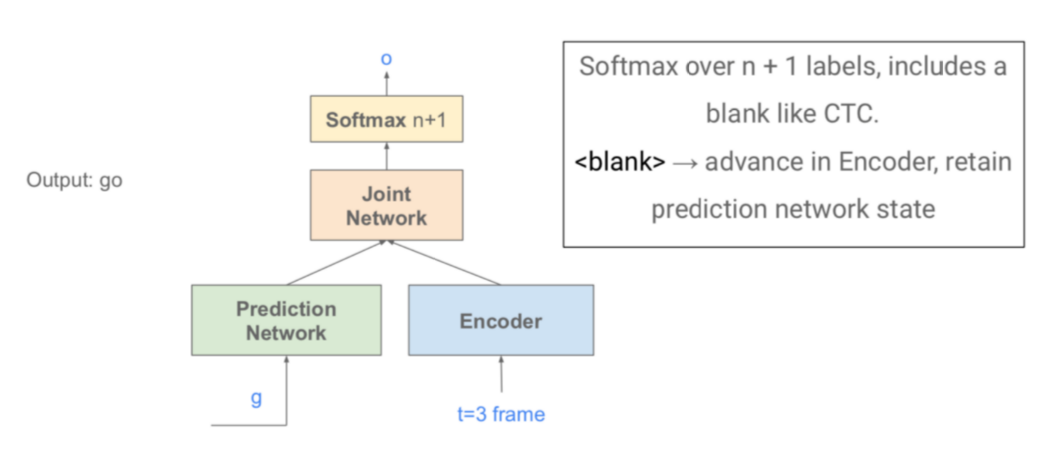
P.S.每一帧解码结束后一般会转到下一帧的处理,因为一帧实在太小了,除非极特殊情况某一帧处于两个音节交界处。
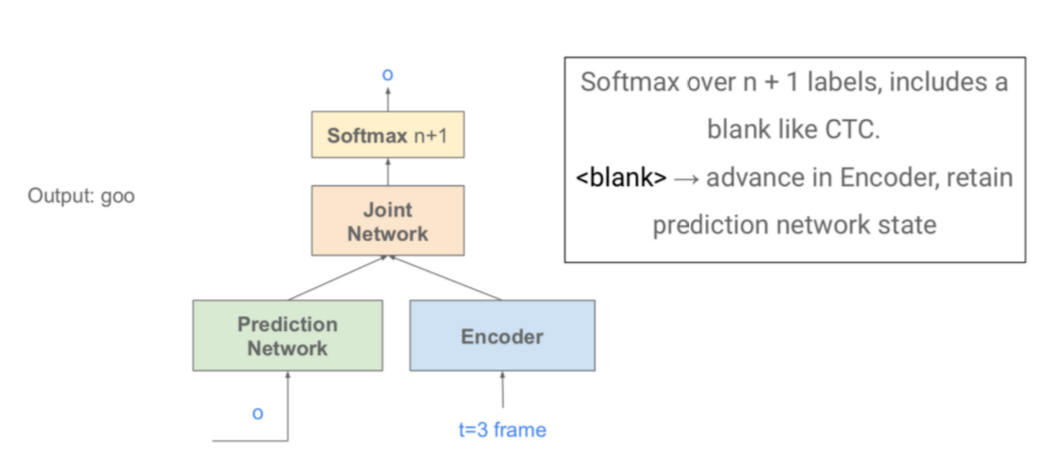
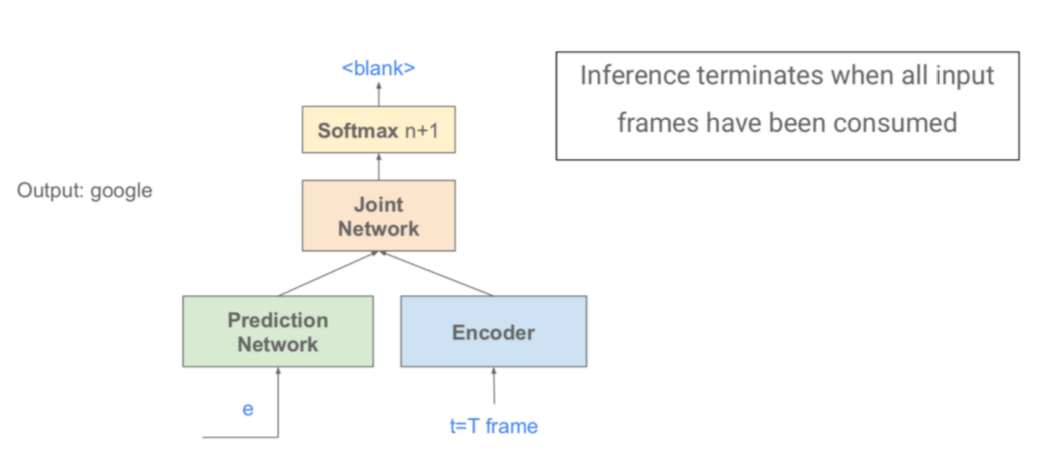
- 使用单向Encoder时,可以进行流式语音识别
- 也就是拿到一帧就可以解码一步LAS
- Speech Transformer等必须等到一句话说完才可以解码
总结小记
Listen, Attend and Spell
特点:encoder-RNN and decoder-RNN
优点:没有输出独立性假设
缺点:无法直接支持流式语音识别、RNN难以并行
Speech Transformer
特点:self-attention替代RNN
优点:self-attention易并行、训练速度快、效果好
缺点:有时对超参很敏感
CTC
特点:只有一个RNN
优点:输入与输出具有单调关系
缺点:输出独立性假设、好性能需要LM
RNN-Transducer
- 加入额外LM的单RNN系统
- 优点:天然支持流式语音识别
- 缺点:Loss计算不易实现,一般用开源库