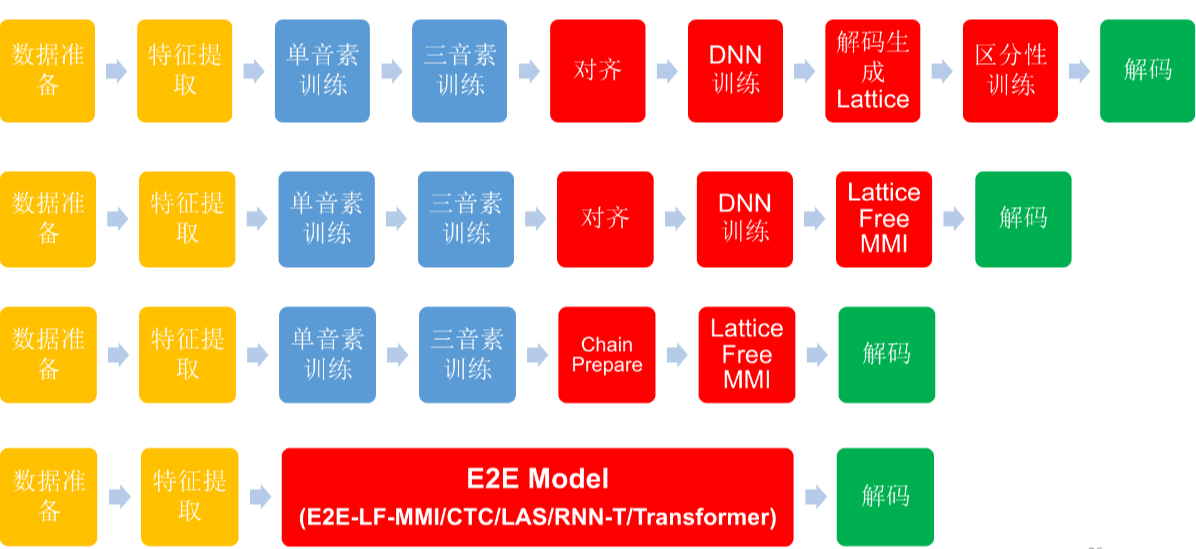
Class 9 区分性训练和LF-MMI
声学模型的训练一般是基于极大似然准则(ML),然而ML只考虑正确路径的优化训练,没有考虑降低其他路径的分数,因此识别效果不佳。
区分性训练目标是提高正确路径得分的同时降低其他路径的得分,加大这些路径间的差异,因此识别效果更好。
区分性训练(Discriminative Training)
最大似然训练
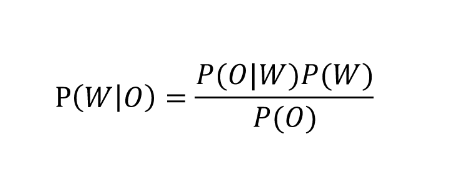
语言模型P(W)
声学模型P(O|W)
最大似然声学模型训练
(ML: Maximum Likelihood)

我们可不可以直接最大化P(W|O) ==> 基于MMI的区分性声学模型训练
MMI: Maximum Mutual Information

ML和MMI
ML仅考虑最大化正确路径(标注)概率
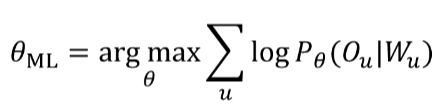
MMI考虑了所有路径产生O_u的概率
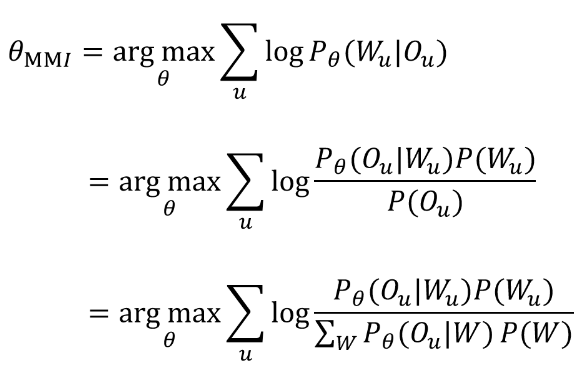
如何优化该式,这是个分式,所以?
- 增大分子(Numerator)
- 减小分母(Denominator)
声学模型P(O|W)
- GMM(均值、方差)
- DNN(网络参数)
ML/MMI in HMM with DNN

MMI(将W展开成HMM state sequence),要计算 γ 必须要给出W的所有可能,W应该是有限空间,可枚举的。
区分性训练其他准则
- MPE: Minimum Phone Error
- sMBR: state- level Minimum Bayes Risk
- MCE: Minimum Classification Error
- bMMI: boosted MMI
Lattice based MMI
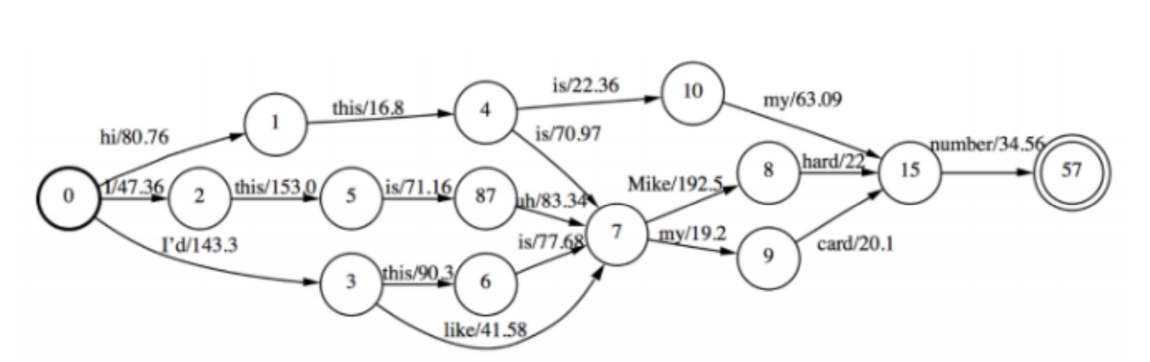
利用原语音解码生成的Lattice来近似所有的W的可能
- 概率低的序列在解码阶段会被及时裁剪掉
- 如何在Lattice上计算γ :前向后向算法
Tricks
- Wider la-ce, 弱语言模型(uni-gram/bi-gram)
Lattice based区分性训练流程

- Lattice生成需要解码,代价很高,一般只在DNN模型的基础上一次生成,模型训练中不重新生成Lattice。
LF-MMI(Lattice Free MMI)
如何表示分母W的所有可能?统计n-gram(Word?Phone?State?)
Lattice free MMI
- 由训练数据训练Phone/State的n-gram(低阶), and no back-off
- WFST Compose成State level的FST
- FST + AM score + 前向后向算法计算
Lattice free MMI 训练流程

Kaldi chain model
Chain model: Lattice Free MMI from scratch, to make it
- Kaldi chain model训练流程

Tricks
LF-MMI Topology
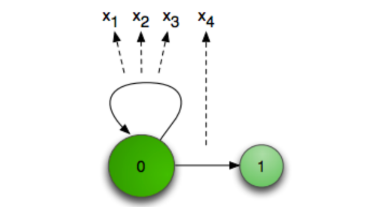
标准的3状态HMM topology —–> LF-MMI topology
Reduce frame rate(10ms to 30ms)【跳帧】
仅用网络输出的1/3计算loss funcaon和梯度,即取t, t+3, t+6, t+9 …,或者相邻的3个t中随机取一个就
行(引入随机性提高鲁棒性),做到训练和解码上的线性加速提升。CE Regularization
使用CE作为第二个Task进行Multi-Task Learning
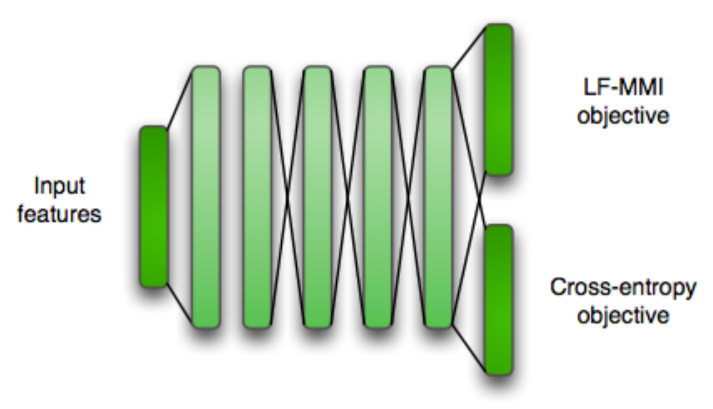
Numerator
- 使用在标注文本上生成的La-ce计算
- 引入时间上的扰动,方便Fixed chunk切分数据。
Denominator
- Phone level 3-gram G, without back-off
- Denominator FST H*C*G
- C is bi-phone instead of tri-phone.(降低分母复杂度)
bi-phone Tree
Fixed chunk
将训练数据切分为固定大小的chunk(1.5s)训练,切分成多个batch,实现DNN并行训练。
总结