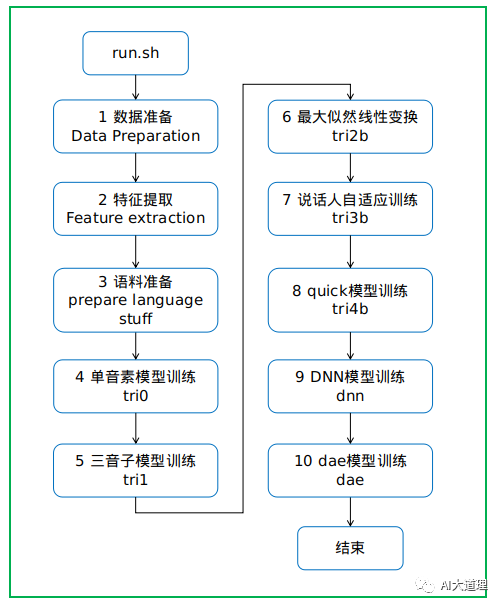
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
| steps/align_fmllr.sh --nj 8 --cmd run.pl data/mfcc/train data/lang exp/tri4b exp/tri4b_ali
tree-info exp/tri4b/tree
tree-info exp/tri4b/tree
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
make-h-transducer --disambig-syms-out=exp/tri4b/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri4b/tree exp/tri4b/final.mdl
fstrmsymbols exp/tri4b/graph_word/disambig_tid.int
fstrmepslocal
fstminimizeencoded
fstdeterminizestar --use-log=true
fsttablecompose exp/tri4b/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
steps/align_fmllr.sh: aligning data in data/mfcc/train using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
ERROR: VectorFst::Read: Read failed: <unspecified>
ERROR (fstdeterminizestar[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:40) Could not read fst from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f4d1b6ad1ce]
fstdeterminizestar(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55ab2291f59d]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x370) [0x7f4d1b711680]
fstdeterminizestar(main+0x244) [0x55ab2291d47c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f4d1afb7d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f4d1afb7e40]
fstdeterminizestar(_start+0x25) [0x55ab2291d165]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmsymbols[5.5.1050~1-0fb50]:ReadFstKaldiGeneric():kaldi-fst-io.cc:59) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f1cacd2d1ce]
fstrmsymbols(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x55761aba4761]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldiGeneric(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool)+0x1c5) [0x7f1cacd90bd1]
fstrmsymbols(main+0x30d) [0x55761aba3bb6]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f1cac71ed90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f1cac71ee40]
fstrmsymbols(_start+0x25) [0x55761aba37e5]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstrmepslocal[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7fd966e901ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7fd966ef55fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7fd966ef44ca]
fstrmepslocal(main+0x1b3) [0x56524d4f7b7c]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7fd96679ad90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7fd96679ae40]
fstrmepslocal(_start+0x25) [0x56524d4f7905]
kaldi::KaldiFatalErrorERROR: FstHeader::Read: Bad FST header: -
ERROR (fstminimizeencoded[5.5.1050~1-0fb50]:ReadFstKaldi():kaldi-fst-io.cc:35) Reading FST: error reading FST header from standard input
[ Stack-Trace: ]
/home/baixf/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0x70c) [0x7f2f0aba41ce]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x25) [0x7f2f0ac095fd]
/home/baixf/kaldi/src/lib/libkaldi-fstext.so(fst::ReadFstKaldi(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)+0x1ba) [0x7f2f0ac084ca]
fstminimizeencoded(main+0x111) [0x5628315c1b5a]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90) [0x7f2f0a595d90]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f2f0a595e40]
fstminimizeencoded(_start+0x25) [0x5628315c1985]
kaldi::KaldiFatalErrorsteps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali/log/analyze_alignments.log
3 warnings in exp/tri4b_ali/log/fmllr.*.log
55 warnings in exp/tri4b_ali/log/align_pass2.*.log
47 warnings in exp/tri4b_ali/log/align_pass1.*.log
steps/align_fmllr.sh --nj 8 --cmd run.pl data/mfcc/dev data/lang exp/tri4b exp/tri4b_ali_cv
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
steps/align_fmllr.sh: aligning data in data/mfcc/dev using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
steps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali_cv
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali_cv/log/analyze_alignments.log
5 warnings in exp/tri4b_ali_cv/log/align_pass1.*.log
6 warnings in exp/tri4b_ali_cv/log/align_pass2.*.log
DNN training: stage 0: feature generation
producing fbank for train
steps/make_fbank.sh --nj 8 --cmd run.pl data/fbank/train exp/make_fbank/train fbank/train
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/train
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for train
steps/compute_cmvn_stats.sh data/fbank/train exp/fbank_cmvn/train fbank/train
Succeeded creating CMVN stats for train
producing fbank for dev
steps/make_fbank.sh --nj 8 --cmd run.pl data/fbank/dev exp/make_fbank/dev fbank/dev
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/dev
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for dev
steps/compute_cmvn_stats.sh data/fbank/dev exp/fbank_cmvn/dev fbank/dev
Succeeded creating CMVN stats for dev
producing fbank for test
Succeeded creating CMVN stats for test
producing test_fbank_phone
# steps/nnet/train.sh --copy_feats false --cmvn-opts "--norm-means=true --norm-vars=false" --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# Started at Wed Aug 31 17:50:20 CST 2022
#
steps/nnet/train.sh --copy_feats false --cmvn-opts --norm-means=true --norm-vars=false --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# INFO
steps/nnet/train.sh : Training Neural Network
dir : exp/tri4b_dnn
Train-set : data/fbank/train 10000, exp/tri4b_ali
CV-set : data/fbank/dev 893 exp/tri4b_ali_cv
LOG ([5.5.1050~1-0fb50]:main():cuda-gpu-available.cc:61)
#
WARNING ([5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:243) Not in compute-exclusive mode. Suggestion: use 'nvidia-smi -c 3' to set compute exclusive mode
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:438) Selecting from 1 GPUs
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:453) cudaSetDevice(0): NVIDIA GeForce GTX 1050 free:3992M, used:47M, total:4040M, free/total:0.98815
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:501) Device: 0, mem_ratio: 0.98815
LOG ([5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:382) Trying to select device: 0
LOG ([5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:511) Success selecting device 0 free mem ratio: 0.98815
LOG ([5.5.1050~1-0fb50]:FinalizeActiveGpu():cu-device.cc:338) The active GPU is [0]: NVIDIA GeForce GTX 1050free:3788M, used:251M, total:4040M, free/total:0.937657 version 6.1
#
#
#
# PREPARING ALIGNMENTS
Using PDF targets from dirs 'exp/tri4b_ali' 'exp/tri4b_ali_cv'
hmm-info exp/tri4b_ali/final.mdl
copy-transition-model --binary=false exp/tri4b_ali/final.mdl exp/tri4b_dnn/final.mdl
LOG (copy-transition-model[5.5.1050~1-0fb50]:main():copy-transition-model.cc:62) Copied transition model.
# PREPARING FEATURES
# + 'apply-cmvn' with '--norm-means=true --norm-vars=false' using statistics : data/fbank/train/cmvn.scp, data/fbank/dev/cmvn.scp
feat-to-dim 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- |' -
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
WARNING (feat-to-dim[5.5.1050~1-0fb50]:Close():kaldi-io.cc:515) Pipe copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | had nonzero return status 36096
# feature dim : 40 (input of 'feature_transform')
# + default 'feature_transform_proto' with splice +/-5 frames,
nnet-initialize --binary=false exp/tri4b_dnn/splice5.proto exp/tri4b_dnn/tr_splice5.nnet
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Splice> <InputDim> 40 <OutputDim> 440 <BuildVector> -5:5 </BuildVector>
LOG (nnet-initialize[5.5.1050~1-0fb50]:main():nnet-initialize.cc:63) Written initialized model to exp/tri4b_dnn/tr_splice5.nnet
# feature type : plain
# compute normalization stats from 10k sentences
compute-cmvn-stats ark:- exp/tri4b_dnn/cmvn-g.stats
nnet-forward --print-args=true --use-gpu=yes exp/tri4b_dnn/tr_splice5.nnet 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- |' ark:-
WARNING (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:243) Not in compute-exclusive mode. Suggestion: use 'nvidia-smi -c 3' to set compute exclusive mode
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:438) Selecting from 1 GPUs
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:453) cudaSetDevice(0): NVIDIA GeForce GTX 1050 free:3992M, used:47M, total:4040M, free/total:0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:501) Device: 0, mem_ratio: 0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:382) Trying to select device: 0
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuIdAuto():cu-device.cc:511) Success selecting device 0 free mem ratio: 0.98815
LOG (nnet-forward[5.5.1050~1-0fb50]:FinalizeActiveGpu():cu-device.cc:338) The active GPU is [0]: NVIDIA GeForce GTX 1050 free:3788M, used:251M, total:4040M, free/total:0.937657 version 6.1
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
LOG (copy-feats[5.5.1050~1-0fb50]:main():copy-feats.cc:143) Copied 10000 feature matrices.
LOG (apply-cmvn[5.5.1050~1-0fb50]:main():apply-cmvn.cc:162) Applied cepstral mean normalization to 10000 utterances, errors on 0
LOG (nnet-forward[5.5.1050~1-0fb50]:main():nnet-forward.cc:192) Done 10000 files in 0.841963min, (fps 181658)
LOG (compute-cmvn-stats[5.5.1050~1-0fb50]:main():compute-cmvn-stats.cc:168) Wrote global CMVN stats to exp/tri4b_dnn/cmvn-g.stats
LOG (compute-cmvn-stats[5.5.1050~1-0fb50]:main():compute-cmvn-stats.cc:171) Done accumulating CMVN stats for 10000 utterances; 0 had errors.
# + normalization of NN-input at 'exp/tri4b_dnn/tr_splice5_cmvn-g.nnet'
nnet-concat --binary=false exp/tri4b_dnn/tr_splice5.nnet 'cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -|' exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:53) Reading exp/tri4b_dnn/tr_splice5.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -|
cmvn-to-nnet --std-dev=1.0 exp/tri4b_dnn/cmvn-g.stats -
LOG (cmvn-to-nnet[5.5.1050~1-0fb50]:main():cmvn-to-nnet.cc:114) Written cmvn in 'nnet1' model to: -
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:82) Written model to exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
#
nnet-info exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
num-components 3
input-dim 40
output-dim 440
number-of-parameters 0.00088 millions
component 1 : <Splice>, input-dim 40, output-dim 440,
frame_offsets [ -5 -4 -3 -2 -1 0 1 2 3 4 5 ]
component 2 : <AddShift>, input-dim 440, output-dim 440,
shift_data ( min -0.00404477, max 0.0024458, mean -0.000288983, stddev 0.000940905, skewness -0.818492, kurtosis 1.721 ) , lr-coef 0
component 3 : <Rescale>, input-dim 440, output-dim 440,
scale_data ( min 0.236916, max 0.392197, mean 0.289203, stddev 0.0389445, skewness 0.623488, kurtosis -0.290958 ) , lr-coef 0
LOG (nnet-info[5.5.1050~1-0fb50]:main():nnet-info.cc:57) Printed info about exp/tri4b_dnn/tr_splice5_cmvn-g.nnet
#
# NN-INITIALIZATION
# getting input/output dims :
feat-to-dim 'ark:copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | nnet-forward "exp/tri4b_dnn/final.feature_transform" ark:- ark:- |' -
copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:-
apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:-
nnet-forward exp/tri4b_dnn/final.feature_transform ark:- ark:-
LOG (nnet-forward[5.5.1050~1-0fb50]:SelectGpuId():cu-device.cc:168) Manually selected to compute on CPU.
WARNING (feat-to-dim[5.5.1050~1-0fb50]:Close():kaldi-io.cc:515) Pipe copy-feats scp:exp/tri4b_dnn/train.scp.10k ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | nnet-forward "exp/tri4b_dnn/final.feature_transform" ark:- ark:- | had nonzero return status 36096
# genrating network prototype exp/tri4b_dnn/nnet.proto
# initializing the NN 'exp/tri4b_dnn/nnet.proto' -> 'exp/tri4b_dnn/nnet.init'
nnet-initialize --seed=777 exp/tri4b_dnn/nnet.proto exp/tri4b_dnn/nnet.init
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 440 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.037344 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 1024 <BiasMean> -2.000000 <BiasRange> 4.000000 <ParamStddev> 0.109375 <MaxNorm> 0.000000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Sigmoid> <InputDim> 1024 <OutputDim> 1024
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <AffineTransform> <InputDim> 1024 <OutputDim> 3392 <BiasMean> 0.000000 <BiasRange> 0.000000 <ParamStddev> 0.074485 <LearnRateCoef> 1.000000 <BiasLearnRateCoef> 0.100000
VLOG[1] (nnet-initialize[5.5.1050~1-0fb50]:Init():nnet-nnet.cc:314) <Softmax> <InputDim> 3392 <OutputDim> 3392
LOG (nnet-initialize[5.5.1050~1-0fb50]:main():nnet-initialize.cc:63) Written initialized model to exp/tri4b_dnn/nnet.init
# RUNNING THE NN-TRAINING SCHEDULER
steps/nnet/train_scheduler.sh --feature-transform exp/tri4b_dnn/final.feature_transform --learn-rate 0.008 exp/tri4b_dnn/nnet.init ark:copy-feats scp:exp/tri4b_dnn/train.scp ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/train/utt2spk scp:data/fbank/train/cmvn.scp ark:- ark:- | ark:copy-feats scp:exp/tri4b_dnn/cv.scp ark:- | apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/dev/utt2spk scp:data/fbank/dev/cmvn.scp ark:- ark:- | ark:ali-to-pdf exp/tri4b_ali/final.mdl "ark:gunzip -c exp/tri4b_ali/ali.*.gz |" ark:- | ali-to-post ark:- ark:- | ark:ali-to-pdf exp/tri4b_ali/final.mdl "ark:gunzip -c exp/tri4b_ali_cv/ali.*.gz |" ark:- | ali-to-post ark:- ark:- | exp/tri4b_dnn
CROSSVAL PRERUN AVG.LOSS 8.4100 (Xent),
ITERATION 01: TRAIN AVG.LOSS 2.0844, (lrate0.008), CROSSVAL AVG.LOSS 2.2329, nnet accepted (nnet_iter01_learnrate0.008_tr2.0844_cv2.2329)
ITERATION 02: TRAIN AVG.LOSS 1.4095, (lrate0.008), CROSSVAL AVG.LOSS 2.0038, nnet accepted (nnet_iter02_learnrate0.008_tr1.4095_cv2.0038)
ITERATION 03: TRAIN AVG.LOSS 1.2454, (lrate0.008), CROSSVAL AVG.LOSS 1.9345, nnet accepted (nnet_iter03_learnrate0.008_tr1.2454_cv1.9345)
ITERATION 04: steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/mono/graph_word exp/mono/decode_test_word
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(3,36,179) and mean=70.2
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/mono/graph_word exp/mono/decode_test_word
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
Traceback (most recent call last):
File "local/wer_output_filter", line 15, in <module>
v = v.encode('utf-8').decode('utf-8')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
steps/decode.sh: Error: scoring failed. (ignore by '--skip-scoring true')
TRAIN AVG.LOSS 1.1448, (lrate0.008), CROSSVAL AVG.LOSS 1.9161, nnet accepted (nnet_iter04_learnrate0.008_tr1.1448_cv1.9161)
ITERATION 05: TRAIN AVG.LOSS 1.0634, (lrate0.004), CROSSVAL AVG.LOSS 1.7115, nnet accepted (nnet_iter05_learnrate0.004_tr1.0634_cv1.7115)
ITERATION 06: TRAIN AVG.LOSS 1.0256, (lrate0.002), CROSSVAL AVG.LOSS 1.5842, nnet accepted (nnet_iter06_learnrate0.002_tr1.0256_cv1.5842)
ITERATION 07: TRAIN AVG.LOSS 1.0191, (lrate0.001), CROSSVAL AVG.LOSS 1.5023, nnet accepted (nnet_iter07_learnrate0.001_tr1.0191_cv1.5023)
ITERATION 08: TRAIN AVG.LOSS 1.0233, (lrate0.0005), CROSSVAL AVG.LOSS 1.4487, nnet accepted (nnet_iter08_learnrate0.0005_tr1.0233_cv1.4487)
ITERATION 09: TRAIN AVG.LOSS 1.0284, (lrate0.00025), CROSSVAL AVG.LOSS 1.4156, nnet accepted (nnet_iter09_learnrate0.00025_tr1.0284_cv1.4156)
ITERATION 10: TRAIN AVG.LOSS 1.0315, (lrate0.000125), CROSSVAL AVG.LOSS 1.3976, nnet accepted (nnet_iter10_learnrate0.000125_tr1.0315_cv1.3976)
ITERATION 11: TRAIN AVG.LOSS 1.0327, (lrate6.25e-05), CROSSVAL AVG.LOSS 1.3882, nnet accepted (nnet_iter11_learnrate6.25e-05_tr1.0327_cv1.3882)
ITERATION 12: TRAIN AVG.LOSS 1.0327, (lrate3.125e-05), CROSSVAL AVG.LOSS 1.3837, nnet accepted (nnet_iter12_learnrate3.125e-05_tr1.0327_cv1.3837)
ITERATION 13: TRAIN AVG.LOSS 1.0323, (lrate1.5625e-05), CROSSVAL AVG.LOSS 1.3816, nnet accepted (nnet_iter13_learnrate1.5625e-05_tr1.0323_cv1.3816)
ITERATION 14: TRAIN AVG.LOSS 1.0318, (lrate7.8125e-06), CROSSVAL AVG.LOSS 1.3806, nnet accepted (nnet_iter14_learnrate7.8125e-06_tr1.0318_cv1.3806)
finished, too small rel. improvement 0.000752729
steps/nnet/train_scheduler.sh: Succeeded training the Neural Network : 'exp/tri4b_dnn/final.nnet'
steps/nnet/train.sh: Successfuly finished. 'exp/tri4b_dnn'
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn/decode_test_phone
steps/nnet/align.sh --nj 8 --cmd run.pl data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_ali
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn/decode_test_word
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/align.sh: aligning data 'data/fbank/train' using nnet/model 'exp/tri4b_dnn', putting alignments in 'exp/tri4b_dnn_ali'
# Accounting: time=6894 threads=1
# Ended (code 0) at Wed Aug 31 19:45:14 CST 2022, elapsed time 6894 seconds
steps/nnet/align.sh: done aligning data.
steps/nnet/make_denlats.sh --nj 8 --cmd run.pl --mem 4G --config conf/decode_dnn.config --acwt 0.1 data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_denlats
Making unigram grammar FST in exp/tri4b_dnn_denlats/lang
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: not warning for OOVs any more times
** Replaced 22 instances of OOVs with 2
Compiling decoding graph in exp/tri4b_dnn_denlats/dengraph
tree-info exp/tri4b_dnn/tree
tree-info exp/tri4b_dnn/tree
fstpushspecial
fstminimizeencoded
fstdeterminizestar --use-log=true
fsttablecompose exp/tri4b_dnn_denlats/lang/L_disambig.fst exp/tri4b_dnn_denlats/lang/G.fst
fstisstochastic exp/tri4b_dnn_denlats/lang/tmp/LG.fst
-0.0323879 -0.0325606
[info]: LG not stochastic.
fstcomposecontext --context-size=3 --central-position=1 --read-disambig-syms=exp/tri4b_dnn_denlats/lang/phones/disambig.int --write-disambig-syms=exp/tri4b_dnn_denlats/lang/tmp/disambig_ilabels_3_1.int exp/tri4b_dnn_denlats/lang/tmp/ilabels_3_1.541227 exp/tri4b_dnn_denlats/lang/tmp/LG.fst
fstisstochastic exp/tri4b_dnn_denlats/lang/tmp/CLG_3_1.fst
0 -0.0325606
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/tri4b_dnn_denlats/dengraph/disambig_tid.int --transition-scale=1.0 exp/tri4b_dnn_denlats/lang/tmp/ilabels_3_1 exp/tri4b_dnn/tree exp/tri4b_dnn/final.mdl
fsttablecompose exp/tri4b_dnn_denlats/dengraph/Ha.fst exp/tri4b_dnn_denlats/lang/tmp/CLG_3_1.fst
fstminimizeencoded
fstdeterminizestar --use-log=true
fstrmepslocal
fstrmsymbols exp/tri4b_dnn_denlats/dengraph/disambig_tid.int
fstisstochastic exp/tri4b_dnn_denlats/dengraph/HCLGa.fst
0.661133 -0.0799874
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri4b_dnn/final.mdl exp/tri4b_dnn_denlats/dengraph/HCLGa.fst
steps/nnet/make_denlats.sh: generating denlats from data 'data/fbank/train', putting lattices in 'exp/tri4b_dnn_denlats'
steps/nnet/make_denlats.sh: done generating denominator lattices.
steps/nnet/train_mpe.sh --cmd run.pl --gpu 1 --num-iters 3 --acwt 0.1 --do-smbr false data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_ali exp/tri4b_dnn_denlats exp/tri4b_dnn_mpe
Pass 1 (learnrate 0.00001)
TRAINING FINISHED; Time taken = 6.98081 min; processed 21905.1 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.977291 over 9174910 frames.
Pass 2 (learnrate 1e-05)
TRAINING FINISHED; Time taken = 7.42708 min; processed 20588.9 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.978551 over 9174910 frames.
Pass 3 (learnrate 1e-05)
TRAINING FINISHED; Time taken = 7.18205 min; processed 21291.3 frames per second.
Done 9998 files, 2 with no reference alignments, 0 with no lattices, 0 with other errors.
Overall average frame-accuracy is 0.979353 over 9174910 frames.
MPE/sMBR training finished
Re-estimating priors by forwarding 10k utterances from training set.
steps/nnet/make_priors.sh --cmd run.pl --nj 8 data/fbank/train exp/tri4b_dnn_mpe
Accumulating prior stats by forwarding 'data/fbank/train' with 'exp/tri4b_dnn_mpe'
Succeeded creating prior counts 'exp/tri4b_dnn_mpe/prior_counts' from 'data/fbank/train'
steps/nnet/train_mpe.sh: Done. 'exp/tri4b_dnn_mpe'
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/3.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it3
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/2.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it2
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/2.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it2
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/1.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it1
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/1.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn_mpe/decode_test_phone_it1
steps/nnet/decode.sh --nj 8 --cmd run.pl --mem 4G --nnet exp/tri4b_dnn_mpe/3.nnet --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn_mpe/decode_test_word_it3
DAE: switching to per-utterance CMVN mode
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_phone/HCLG.fst
steps/compute_cmvn_stats.sh data/fbank/train exp/fbank_cmvn/train.per_utt fbank/per_utt
Succeeded creating CMVN stats for train
steps/compute_cmvn_stats.sh data/fbank/dev exp/fbank_cmvn/dev.per_utt fbank/per_utt
Succeeded creating CMVN stats for dev
steps/compute_cmvn_stats.sh data/fbank/test exp/fbank_cmvn/test.per_utt fbank/per_utt
Succeeded creating CMVN stats for test
steps/compute_cmvn_stats.sh data/fbank/test_phone exp/fbank_cmvn/test_phone.per_utt fbank/per_utt
Succeeded creating CMVN stats for test_phone
DAE: generate training data...
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/train exp/dae/gendata fbank/dae/train
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/train
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for train
steps/compute_cmvn_stats.sh data/dae/train exp/dae/cmvn fbank/dae/train
Succeeded creating CMVN stats for train
DAE: generating dev data...
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/dev/0db exp/dae/gendata fbank/dae/dev/0db
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/dev/0db
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for 0db
steps/compute_cmvn_stats.sh data/dae/dev/0db exp/dae/cmvn fbank/dae/dev/0db
Succeeded creating CMVN stats for 0db
DAE: generating test data...
producing fbanks for car
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/car exp/dae/gendata fbank/dae/test/0db/car
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/car
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for car
generating cmvn for test data car
steps/compute_cmvn_stats.sh data/dae/test/0db/car exp/dae/cmvn fbank/dae/test/0db/car
Succeeded creating CMVN stats for car
producing fbanks for white
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/white exp/dae/gendata fbank/dae/test/0db/white
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/white
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for white
generating cmvn for test data white
steps/compute_cmvn_stats.sh data/dae/test/0db/white exp/dae/cmvn fbank/dae/test/0db/white
Succeeded creating CMVN stats for white
producing fbanks for cafe
steps/make_fbank.sh --nj 8 --cmd run.pl data/dae/test/0db/cafe exp/dae/gendata fbank/dae/test/0db/cafe
utils/validate_data_dir.sh: Successfully validated data-directory data/dae/test/0db/cafe
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
steps/make_fbank.sh: Succeeded creating filterbank features for cafe
generating cmvn for test data cafe
steps/compute_cmvn_stats.sh data/dae/test/0db/cafe exp/dae/cmvn fbank/dae/test/0db/cafe
Succeeded creating CMVN stats for cafe
feat-to-dim scp:exp/tri4b_dnn_dae/tgt_feats.scp -
num_fea = 40
nnet-concat exp/tri4b_dnn_dae/final.feature_transform exp/tri4b_dnn_dae/final.nnet exp/tri4b_dnn_mpe/final.feature_transform exp/tri4b_dnn_dae/dae.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:53) Reading exp/tri4b_dnn_dae/final.feature_transform
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating exp/tri4b_dnn_dae/final.nnet
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:65) Concatenating exp/tri4b_dnn_mpe/final.feature_transform
LOG (nnet-concat[5.5.1050~1-0fb50]:main():nnet-concat.cc:82) Written model to exp/tri4b_dnn_dae/dae.nnet
DAE: switch bach to per-speaker CMVN mode
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/car exp/tri4b_dnn_mpe/decode_word_0db/car
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/white exp/tri4b_dnn_mpe/decode_word_0db/white
steps/nnet/decode.sh --cmd run.pl --mem 4G --nj 8 --srcdir exp/tri4b_dnn_mpe exp/tri4b/graph_word data/dae/test/0db/cafe exp/tri4b_dnn_mpe/decode_word_0db/cafe
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
steps/nnet/decode.sh: missing file exp/tri4b/graph_word/HCLG.fst
|