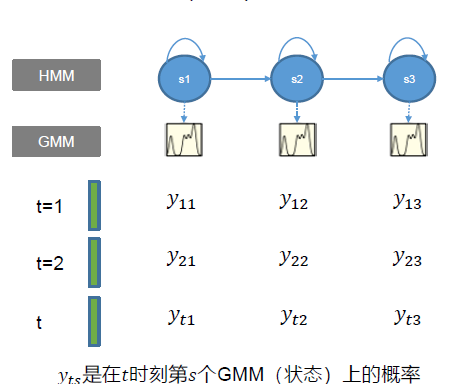
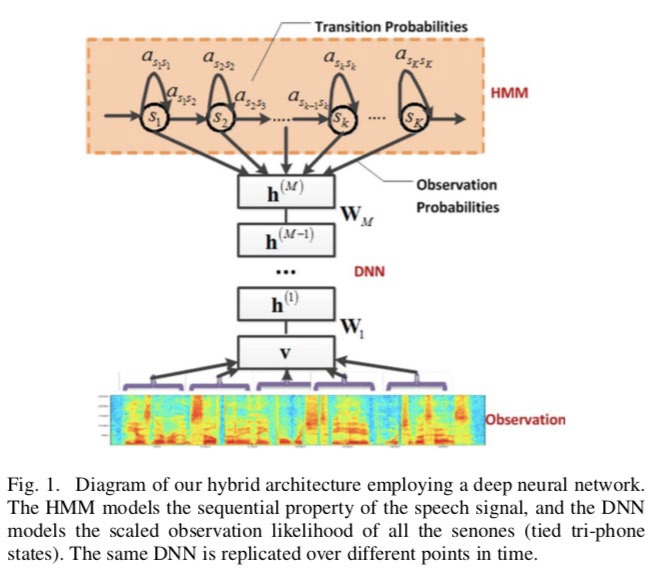
GMM-HMM语音识别系统 建模训练 对于每一个语音序列先进行特征提取,得到每一个特征序列,再通过HMM-GMM建模。
对于每个状态有一个GMM模型,对于每个词有一个HMM模型,当一段语音输入后,根据Viterbi算法得到一个序列在GMM-HMM上的概率,然后通过Viterbi回溯得到每帧属于HMM的哪个状态(对齐)。
解码 对于任何一个特征序列,我们都可以通过GMM-HMM模型得到在任意时刻任意状态上的一个观测的概率,应用Veterbi算法结合HMM的转移概率和观测序列就可以进行解码。
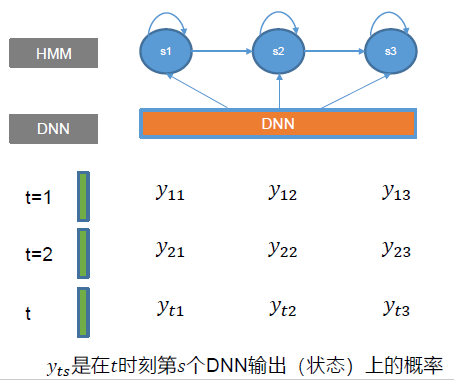
问题:GMM对概率密度进行建模的话,也可以使用DNN来实现,本质上就是一个分类的模型。假设整个系统有如上图的特征向量和三个状态,我们就可以建立一个输出为3的神经网络,这里GMM就替换成了DNN。
DNN-HMM语音识别系统 建模训练 原始语音经过特征提取以后得到相应的13维的频谱特征(Fbank or MFCC),频谱特征经过神经网络DNN做一个状态上的分类模型,对于任何一段语音的训练数据来讲,我们有语音和其对应的label,对齐以后,我们可以得到这段语音对应状态的序列,然后我们就得到新的label和对应的原始语音,就可以通过DNN来训练了。
DNN三要素:
输入是什么?频谱特征
输出是什么?频谱特征所对应的状态label
损失函数是什么?分类问题CrossEntropy
然后,硬train一发 就可以了
解码 同上HMM-GMM模型,对于任何一个特征序列,我们都可以通过DNN-HMM模型得到在任意时刻任意状态上的一个观测的概率,应用Veterbi算法结合HMM的转移概率和观测序列就可以进行解码。
整体流程
Kaldi中AISHELL: egs/aishell/s5/run.sh
1.数据准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 数据下载 # Lexicon Preparation,词典准备 # Data Preparation,kaldi所需要的数据格式的准备 # Phone Sets, questions, L compilation,准备音素集,问题集,? # LM training,language model? # G compilation, check LG composition,fft的知识?
2.特征提取
1 2 3 4 5 6 7 8 9 10 # Now make MFCC plus pitch features. # mfccdir should be some place with a largish disk where you # want to store MFCC features. # 使用的是MFCC + 基频的特征
3.单音素训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # Train a monophone model on delta features. # Decode with the monophone model.解码相关,对单音素模型进行一个评估,计算其识别率 # Get alignments from monophone system.使用单音素来做一个对齐操作,为下一步Veterbi做准备
4.三音素训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 # 进行了多次训练,每一次都有训练+解码+对齐 # Train the first triphone pass model tri1 on delta + delta-delta features. # decode tri1 # align tri1 # train tri2 [delta+delta-deltas] # decode tri2 # Align training data with the tri2 model. # Train the second triphone pass model tri3a on LDA+MLLT features. # Run a test decode with the tri3a model. # align tri3a with fMLLR # Train the third triphone pass model tri4a on LDA+MLLT+SAT features. # From now on, we start building a more serious system with Speaker # Adaptive Training (SAT). # decode tri4a # align tri4a with fMLLR # Train tri5a, which is LDA+MLLT+SAT # Building a larger SAT system. You can see the num-leaves is 3500 and tot-gauss is 100000 # decode tri5a # align tri5a with fMLLR
5.DNN的训练
1 2 3 4 5 # nnet3,TDNN是DNN的一种变种,以tri5a的输出作为输入 # chain
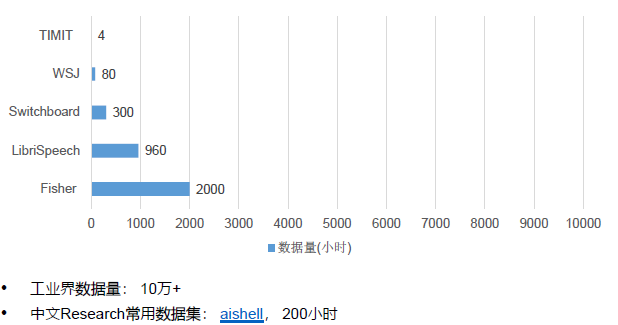
深度神经网络 语音识别数据集
语音开源数据汇总:Open Speech and Language Resources
语音领域学术会议
ASR性能指标
句错误率(SER,Sentence Error Rate)
$$
词错率(WER,Word error rate)
Total Words 为(S替换+ D删除+ H正确)的字数
$$
字错误率(CER,Character Error Rate)
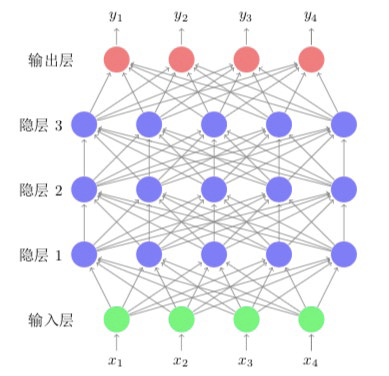
FNN(Feedforward Neural Network) $${l} x+\boldsymbol{b} {l}\right)
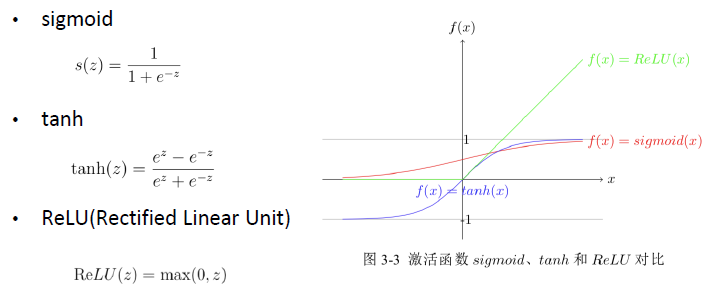
激活函数 f是一种激活函数,常见的激活函数有:
损失函数 NN分类问题的损失函数:
归一化是把数据压缩到[0,1],把量纲转为无量纲的过程,方便计算、比较。softmax是依赖于交叉熵设计的,因为交叉熵在计算的时候需要用到反向传播机制,反向传播对应的就是链式求导,如果用softmax的话就刚好和交叉熵求导的分母抵消掉,从而减小误差。
$$
相对熵描述的是两个概率分布分布之间的差异,所以本应该是使用相对熵来计算真实分布与预测分布之间的差异。但是,相对熵 = 交叉熵 - 信息熵,而信息熵描述的是消除 p pp (即真实分布) 的不确定性所需信息量,是个固定值,因此优化相对熵可以简化为优化交叉熵,故机器学习中使用交叉熵作为损失函数
$$
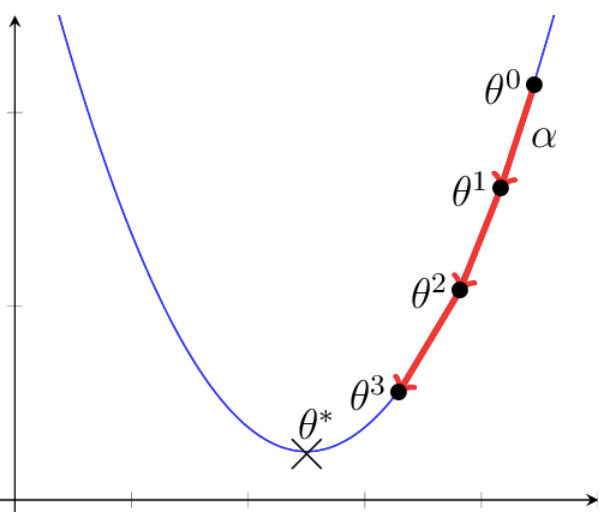
梯度下降
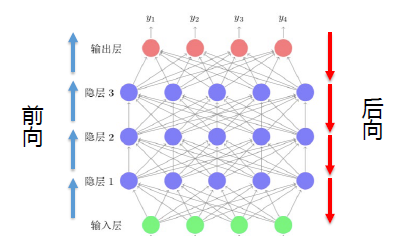
反向传播(BackPropagation)
$$
训练流程 1 2 3 4 5 6 7 8 9 10 11 for epoch in range (max_epoch) :for minibatch in data:input ,label = minibatchinput )
其他NN必备知识
Optimizer(SGD/Momentum/Adam …)
Dropout
Regularization(正则化)
ResidualConnection
BatchNormalization
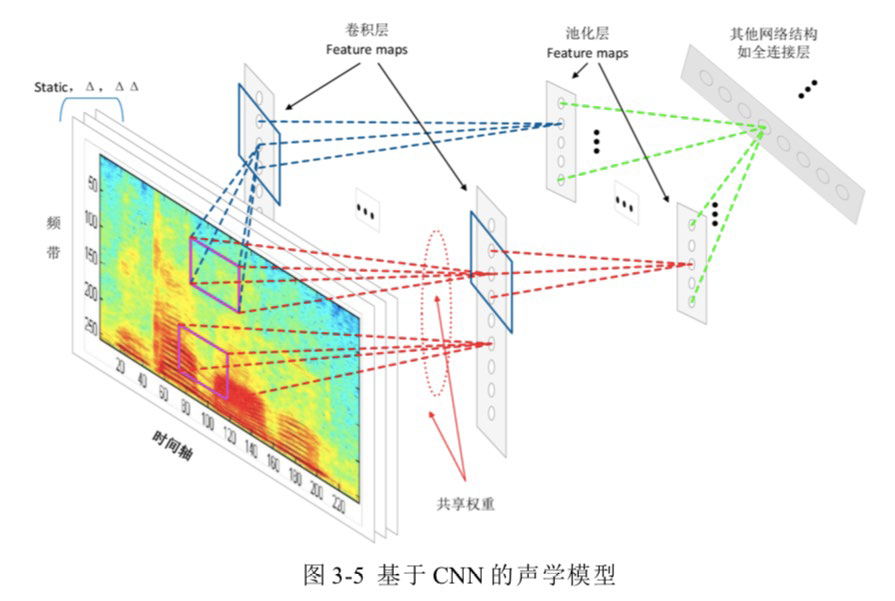
CNN
Convolution(卷积,特征提取) + Pooling(池化层,降维)
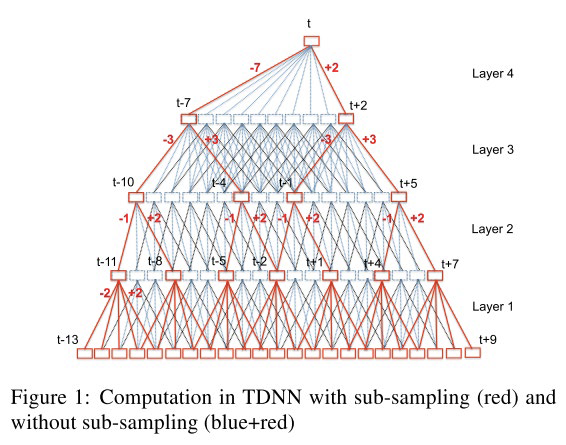
TDNN
RNN(Recurrent Neural Network)
网络结构有记忆的功能,因此适合基于时序的建模。
LSTM (Long Short Term Memory)
RNN特别不稳定,容易出现梯度弥散或者梯度爆炸的问题,所以模型训练效果不好。
LSTMP(LSTM with projection)
该变种的主要目的是为了减小模型参数 。与传统的LSTM相比,LSTMP在记忆块(memory blocks)与模型的输出层之间引入了映射层。通过加入了映射层,模型参数能得到有效减少。
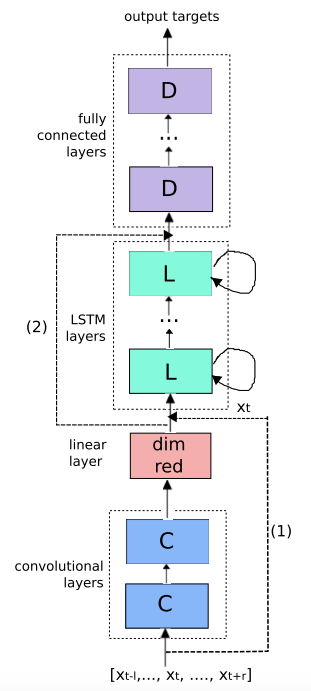
混合神经网络(CLDNN)
FNN
CNN
局部特征抽取
Invariance
有限时序建模能力
RNN
复杂网络基本是以上三种网络的组合
参考