Class1 语音识别综述
一、语音
语音
语音是语言的物质外壳,即语言的声学表现形式
语音是人类自然的交流工具
语音通信
人机语音交互

声学(Acoustics)
音频(Audio):采样率、量化位数、通道数(例16KHz, 16bit, Mono)
语音(Speech)编码/格式:参数编码、波形编码、混合编码(例PCM(WAV)、MP3、SLIK…)
时域:波形的振幅、频率
频域:
傅里叶分析:每个复杂的波形都可以有不同频率的正弦波组成
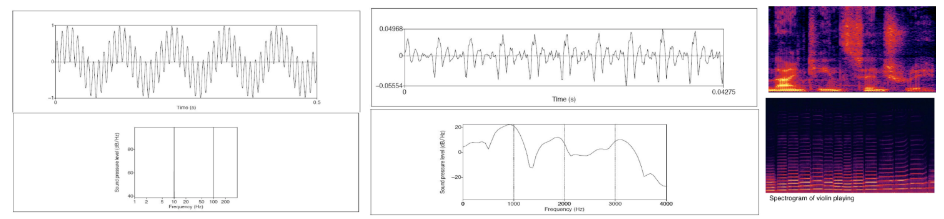
语谱(spectrum): 述了信号包含的频率成分和它们的幅度
语谱图(spectrogram):语谱随时间的变化
二、语音识别
- 什么是语音识别
Automatic Speech Recognition (ASR) 或 Speech to Text (STT)
Aim: 解决机器听清问题,不在意理解
将语音转换成文本
解决机器“听清”问题,不处理“听懂”问题
但是要处理声学和(部分)语言上的混淆
解决“共性”问题:每个人的语音都能 识别出正确的文本
狭义语音识别不包含以下几个部分:说话人(声纹)识别;副语言(paralinguistic aspects)信息的分析与识别(例如发音质量感情韵律);言语理解(褒贬)

- 语音识别评估
Error Rate = (Substitutions + Deletions+ Insertions) / (Total Words in Reference transcripts)
错误类型:S-替换词错误;D-删除词错误 ;I-插入词错误;R-正确抄本;
注意:Error Rate有可能超过100%;
准确率(Accuracy)= 1 - 错误率
- 音素错误率 (Phone Error Rate)
- 词错误率 (Word Error Rate, WER)
- 字错误率 (Character Error Rate, CER)
- 句错误率 (Sentence Error Rate, SER)(语音搜索)
Efficiency:实时率 (Real-time Factor, RTF)
例:10s语音5s识别 RTF=0.5
- 语音识别系统分类
- 说话人:特定人、非特定人
- 语种:单一语种、多语种
- 词汇量:大、中、小(OOV:Out of Vocabulary)
- 设备:云侧、端侧
- 距离:近讲、远讲…
三、语音交互
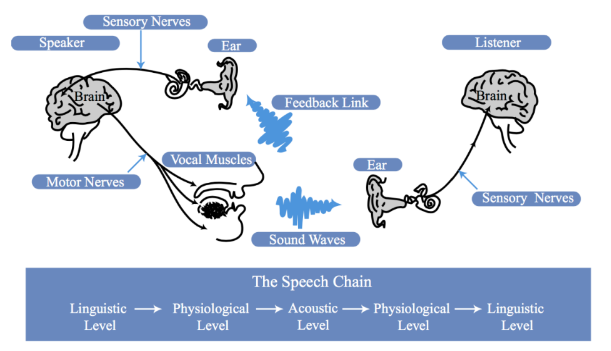
Speech Chain
level: A to B;B to A; A to A; B to B?
四、语音生成
Speech Production: 大脑—神经肌肉命令—发音器官运动
- 发音过程
由于 声门(Glottis) 的肌肉张力,加上由 肺部 压迫出来的空气,就会造成声门的快速打开与关闭,这一疏一密的空气压力,即为 人声源头 ,再经 声道、口腔、鼻腔 的共振,就会产生不同声音。
声门震动的快慢,决定声音的基本频率(即音高)。
口腔、鼻腔、舌头的位置、嘴型等,决定声音的内容(即音色)。
肺部压缩空气力量的大小,决定音量
Source-Filter Model
发音是由信号源(声门),经过滤波器(口腔、鼻腔、 嘴型等)产生
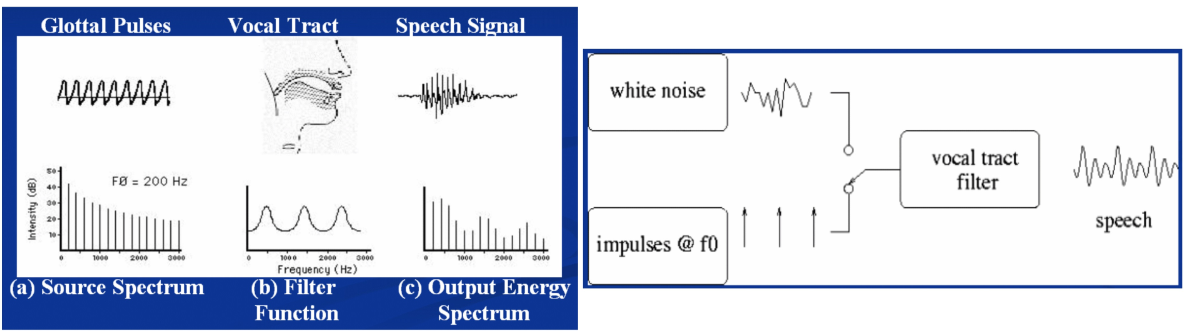
浊音(Voiced sound): 声带振动引起,声音波形具有明显周期 性,声带震动的频率称为基音频率或基频(fundamental frequency, F0),人们可以感受到稳定的音高存在。
清音(Unvoiced sound): 声带不震动,波形类似白噪,人们无 法感受到稳定的音高存在
- 清音与浊音在波形和语谱上的表现
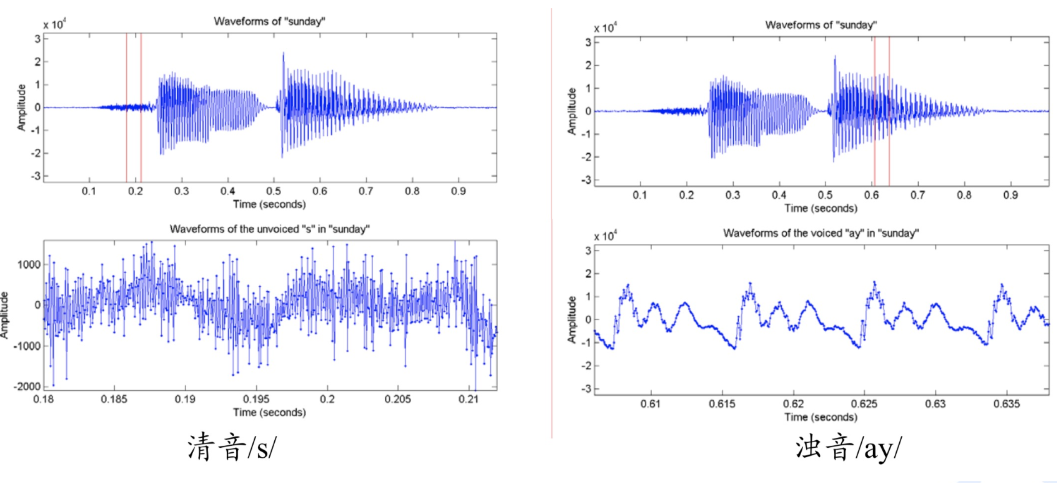
- 清音杂论无序,无高峰差异
- 浊音波形较为规律,由各个小峰组成,共振峰较为明显,短时能量较高。
- 基频(F0)与共振峰(F1,F2,F3)
基音频率体现的是声源的信息,而共振峰(formant)体现的是声道的信息。

共振峰指在声音的频谱中能量相对集中的一些区域(语谱峰值)
共振峰是被声道特别放大的频带; 由于不同元音在声道内不同位置产生,不同元音会产生不同种类的放大或共振。
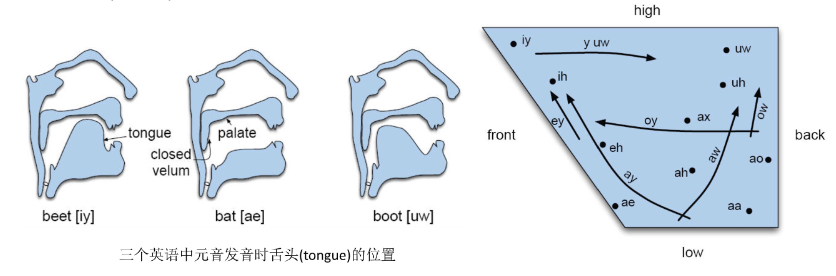
第一和第二个共振峰(F1和F2)对于区分不同元音尤为重要(不同元音F1与F2有不同位置)。
P.S基音和共振峰是不同的两个量,基音是声带振动产生的;而共振峰是口(鼻)腔耦合共振产生的。同一个基频如果口(鼻)腔的形状不同有不同的共振峰,同样不同的基频相同的口(鼻)腔,产生相同的音。所以它们之间没有直接的关系,但只有(带基音的)激励脉冲通过口(鼻)腔的耦合才能产生语音。
- 音素与词素
音素(Phonemes):一种语言中语音的“最小”单元(primitive sounds)(P.S对语音识别进行声学建模是以音素为单位的)
辅音(consonants):由限制或阻挡气流产生,可以是浊音或清音
元音(vowels):声腔开放,气流较为顺畅的通过,通常为浊音,比辅音声音洪亮且持续时间长
词/语素(morpheme):一种语言中最小的具有语义的结构单元
区别于音素,词素是构成词的要素。是语言中最小单位的音义结合体。词素是比词低一级的单位,词是语言中能够独立运用的最小单位,是指词在句法结构中的地位和作用而言的。语素是指语言中最小的音义结合体。
- 协同发音
音素在声学上的实现和上下文强相关 –> 上下文相关模型(Context-dependent model)
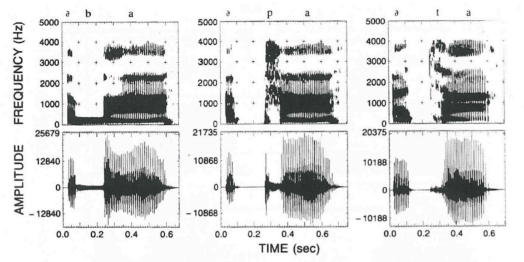
- 音素抄本(Phonetic Transcription)
- 一段语音对应的音素列表(带或不带时间边界,时间信息由人工标注或者自动对齐获得)
- 服务于语音识别声学建模
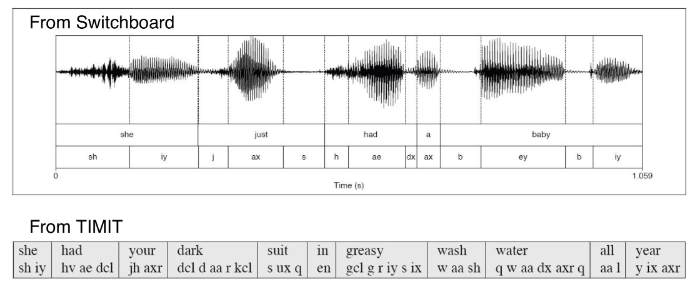
- 音节:元音和辅音结合构成一个音节
Onset:音节头;rime:韵母;nucleus:音节核;coda:音节尾
- 语音生成与语音识别
- 解析出来的发音特征(articulatory features) or 属性(attributes)—效果有限
- 对语音信号处理层面仍有指导意义
- 源-滤波器模型(source-filter model)
- 声道调制中分离出激励信息,如对英文来说激励的频率可以忽略,
对中文来说则可以利用
- 对建模单元的选取有指导意义
- 协同发音(co-articulation)— 上下文相关模型
- 发音上下文现象类似 — 决策树聚类
五、语音感知
Speech Perception: 人耳—大脑
- 人耳:“频谱分析仪”,作为语音处理中频率分析的证据(心理物理学)
- 人耳构成
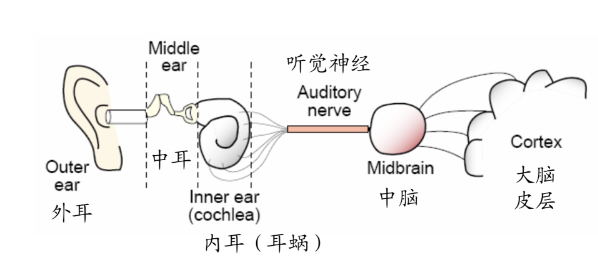
- 物理特性 vs. 听觉特性(physical vs. perceptual)
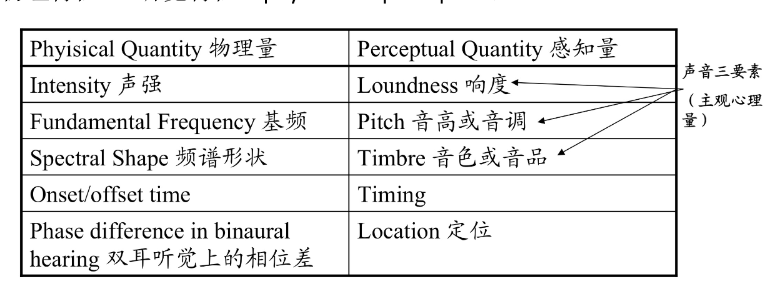
- 音色:又称音品,由声音波形的谐波频谱和包络决定。
- 音调:人耳对于频率的感知是非线性的,近似对数函数。
- 掩蔽效应(Masking):一种心理声学现象,是由人耳对声音频率分辨机制决定的。是指一个较强声音的附近,相对较弱的声音不易被人耳察觉,即被强音所掩蔽。
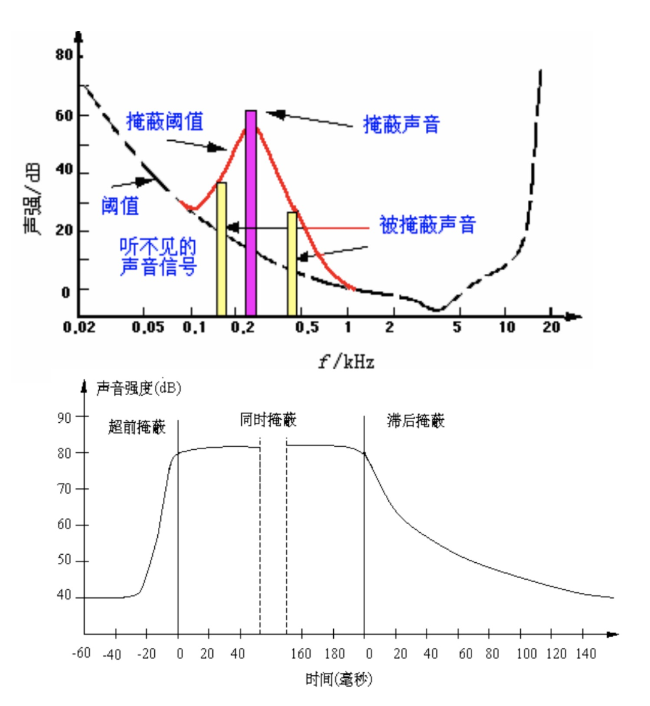
语音感知与语音识别(语音信号处理与特征提取)
- 特征工程, Mel Frequency Cepstral Coefficients (MFCC),PLP…
- 语音编码、增强、分离与麦克风阵列技术…

六、语音识别的难度

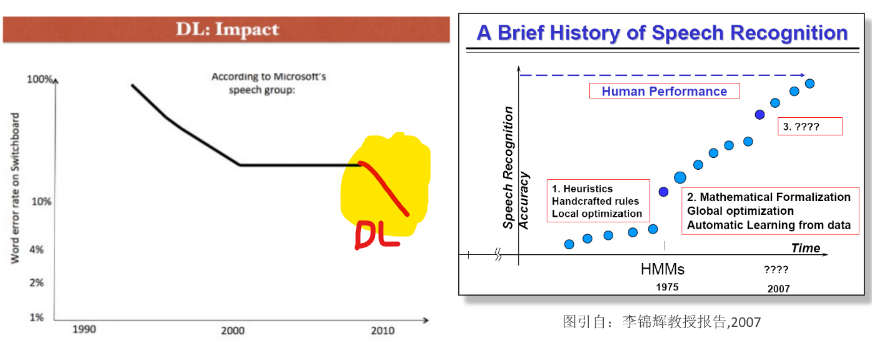
七、语音识别的发展历史
早期个别方法: 1950-1960年代
谱分析,线性预测,统计训练,动态规划(DTW),语言模型
现代语音识别的诞生:1970-1980年代
监督学习,GMM, HMM, N-gram
平稳发展期:1990-2000年代
GMM-HMM框架主导
八、现代语音识别
统计模型
使用声学模型、语言模型和发音词典,通过给定的声学特征向量X,获取最有可能的词序列W*
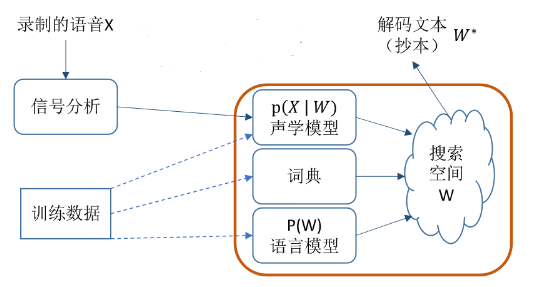
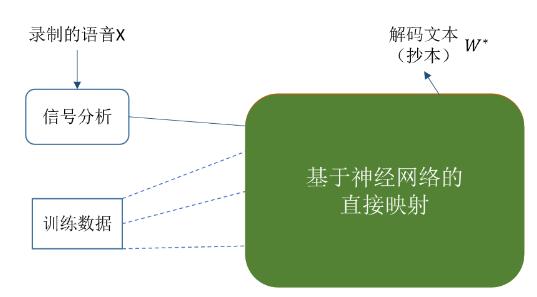
端到端系统
用一个神经网络直接将输入声学特征向量X映射为词序列W*