深度学习超参数介绍及调参
一、超参数概念
- 什么是超参数,参数和超参数的区别?
区分两者最大的一点就是是否通过数据来进行调整,模型参数通常是有数据来驱动调整,超参数则不需要数据来驱动,而是在训练前或者训练中人为的进行调整的参数。例如卷积核的具体核参数就是指模型参数,这是有数据驱动的。而学习率则是人为来进行调整的超参数。这里需要注意的是,通常情况下卷积核数量、卷积核尺寸这些也是超参数,注意与卷积核的核参数区分。
- 神经网络中包含哪些超参数?
通常可以将超参数分为三类:网络参数、优化参数、正则化参数。
网络参数:可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
优化参数:一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数。
正则化:权重衰减系数,丢弃法比率(dropout)
- 为什么要进行超参数调优?
本质上,这是模型优化寻找最优解和正则项之间的关系。网络模型优化调整的目的是为了寻找到全局最优解(或者相比更好的局部最优解),而正则项又希望模型尽量拟合到最优。两者通常情况下,存在一定的对立,但两者的目标是一致的,即最小化期望风险。模型优化希望最小化经验风险,而容易陷入过拟合,正则项用来约束模型复杂度。所以如何平衡两者之间的关系,得到最优或者较优的解就是超参数调整优化的目的。
二、超参数的重要性顺序
首先, 学习率,损失函数上的可调参数。在网络参数、优化参数、正则化参数中最重要的超参数可能就是学习率了。学习率直接控制 着训练中网络梯度更新的量级,直接影响着模型的有效容限能力;损失函数上的可调参数,这些参数通常情况下需要结合实际的损失函数来调整,大部分情况下这些参数也能很直接的影响到模型的的有效容限能力。这些损失一般可分成三类,第一类辅助损失结合常见的损失函数,起到辅助优化特征表达的作用。例如度量学习中的Center loss,通常结合交叉熵损失伴随一个权重完成一些特定的任务。
这种情况下一般建议辅助损失值不高于或者不低于交叉熵损失值的两个数量级;第二类,多任务模型的多个损失函数,每个损失函数之间或独立或相关,用于各自任务,这种情况取决于任务之间本身的相关性,目前笔者并没有一个普适的经验由于提供参考;第三类,独
立损失函数,这类损失通常会在特定的任务有显著性的效果。例如RetinaNet中的focal loss,其中的参数γ,α,对最终的效果会产生较大的影响。这类损失通常论文中会给出特定的建议值。
其次,批样本数量,动量优化器(Gradient Descent with Momentum)的动量参数β。批样本决定了数量梯度下降的方向。过小的批数量,极端情况下,例如batch size为1,即每个样本都去修正一次梯度方向,样本之间的差异越大越难以收敛。若网络中存在批归一化(batchnorm),batch size过小则更难以收敛,甚至垮掉。这是因为数据样本越少,统计量越不具有代表性,噪声也相应的增加。而过大的batch size,会使得梯度方向基本稳定,容易陷入局部最优解,降低精度。一般参考范围会取在[1:1024]之间,当然这个不是绝对的,需要结合具体场景和样本情况;动量衰减参数β是计算梯度的指数加权平均数,并利用该值来更新参数,设置为 0.9 是一个常见且效果不错的选择;
最后,Adam优化器的超参数、权重衰减系数、丢弃法比率(dropout)和网络参数。在这里说明下,这些参数重要性放在最后并不等价于这些参数不重要。而是表示这些参数在大部分实践中不建议过多尝试,例如Adam优化器中的β1,β2, ε ,常设为 0.9、 0.999、10−8就会有不错的表现。权重衰减系数通常会有个建议值,例如0.0005 ,使用建议值即可,不必过多尝试。dropout通常会在全连接层之间使用防止过拟合,建议比率控制在[0.2,0.5]之间。使用dropout时需要特别注意两点:一、在RNN中,如果直接放 在memory cell中,循环会放大噪声,扰乱学习。一般会建议放在输入和输出层;二、不建议dropout后直接跟上batchnorm,dropout很可能影响batchnorm计算统计量,导致方差偏移,这种情况下会使得推理阶段出现模型完全垮掉的极端情况;网络参数通常也属于超参数的范围内,通常情况下增加网络层数能增加模型的容限能力,但模型真正有效的容限能力还和样本数量和质量、层之间的关系等有关,所以一般情况下会选择先固定网络层数,调优到一定阶段或者有大量的硬件资源支持可以在网络深度上进行进一步调整。
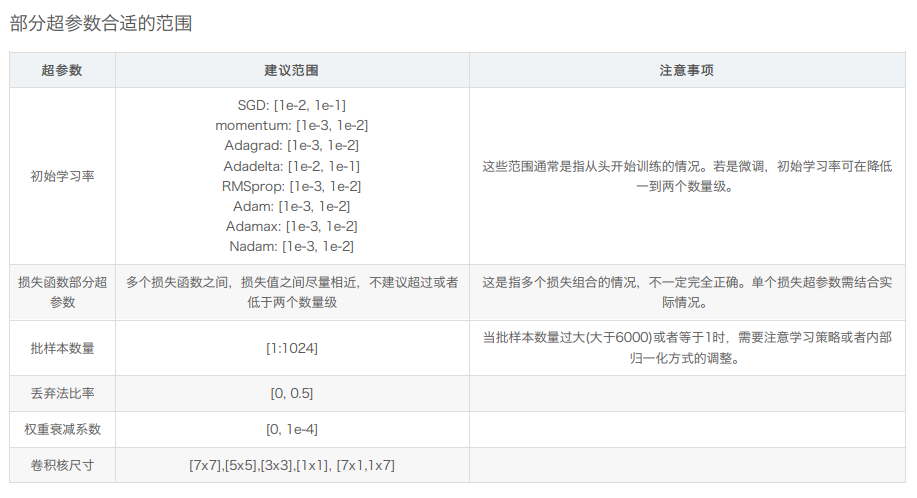
三、部分超参数如何影响模型性能?

四、网络训练中的超参调整策略
- 如何调试模型?
在讨论如何调试模型之前,我们先来纠正一个误区。通常理解如何调试模型的时候,我们想到一系列优秀的神经网络模型以及调试技巧。但这里需要指出的是数据才是模型的根本,如果有一批质量优秀的数据,或者说你能将数据质量处理的很好的时候,往往比挑选或者设计模型的收益来的更大。那在这之后才是模型的设计和挑选以及训练技巧上的事情。
1、探索和清洗数据。探索数据集是设计算法之前最为重要的一步,以图像分类为例,我们需要重点知道给定的数据集样本类别和各类别样本数量是否平衡,图像之间是否存在跨域问题(例如网上爬取的图像通常质量各异,存在噪声)。若是类别数远远超过类别样本数(比如类别10000,每个类别却只有10张图像),那通常的方法可能效果并不显著,这时候few-shot learning或者对数据集做进一步增强可能是你比较不错的选择。再如目标检测,待检测目标在数据集中的尺度范围是对检测器的性能有很大影响的部分。因此重点是检测大目标还是小目标、目标是否密集完全取决于数据集本身。所以,探索和进一步清洗数据集一直都是深度学习中最重要的一步。这是很多新手通常会忽略
的一点。
2、探索模型结果。探索模型的结果,通常是需要对模型在验证集上的性能进行进一步的分析,这是如何进一步提升模型性能很重要的步骤。将模型在训练集和验证集都进行结果的验证和可视化,可直观的分析出模型是否存在较大偏差以及结果的正确性。以图像分类为例,若类别间样本数量很不平衡时,我们需要重点关注少样本类别在验证集的结果是否和训练集的出入较大,对出错类别可进一步进行模型数值分析以及可视化结果分析,进一步确认模型的行为。
3、监控训练和验证误差。首先很多情况下,我们忽略代码的规范性和算法撰写正确性验证,这点上容易产生致命的影响。在训练和验证都存在问题时,首先请确认自己的代码是否正确。其次,根据训练和验证误差进一步追踪模型的拟合状态。若训练数据集很小,此时监控误差则显得格外重要。确定了模型的拟合状态对进一步调整学习率的策略的选择或者其他有效超参数的选择则会更得心应手。
- 为什么要做学习率调整?
学习率可以说是模型训练最为重要的超参数。通常情况下,一个或者一组优秀的学习率既能加速模型的训练,又能得到一个较优甚至最优的精度。过大或者过小的学习率会直接影响到模型的收敛。我们知道,当模型训练到一定程度的时候,损失将不再减少,这时候模型的一阶梯度接近零,对应Hessian 矩阵通常是两种情况,一、正定,即所有特征值均为正,此时通常可以得到一个局部极小值,若这个局部极小值接近全局最小则模型已经能得到不错的性能了,但若差距很大,则模型性能还有待于提升,通常情况下后者在训练初最常见。二,特征值有正有负,此时模型很可能陷入了鞍点,若陷入鞍点,模型性能表现就很差。以上两种情况在训练初期以及中期,此时若仍然以固定的学习 率,会使模型陷入左右来回的震荡或者鞍点,无法继续优化。所以,学习率衰减或者增大能帮助模型有效的减少震荡或者逃离鞍点。