背景
玩家评论可以为游戏的版本迭代提供重要参考,假如可以快速定位玩家的负面评价,则能够节约收集意见的时间成本。本项目通过文本挖掘方法,展示从数据采集到情感模型评价的全过程。
一、爬虫
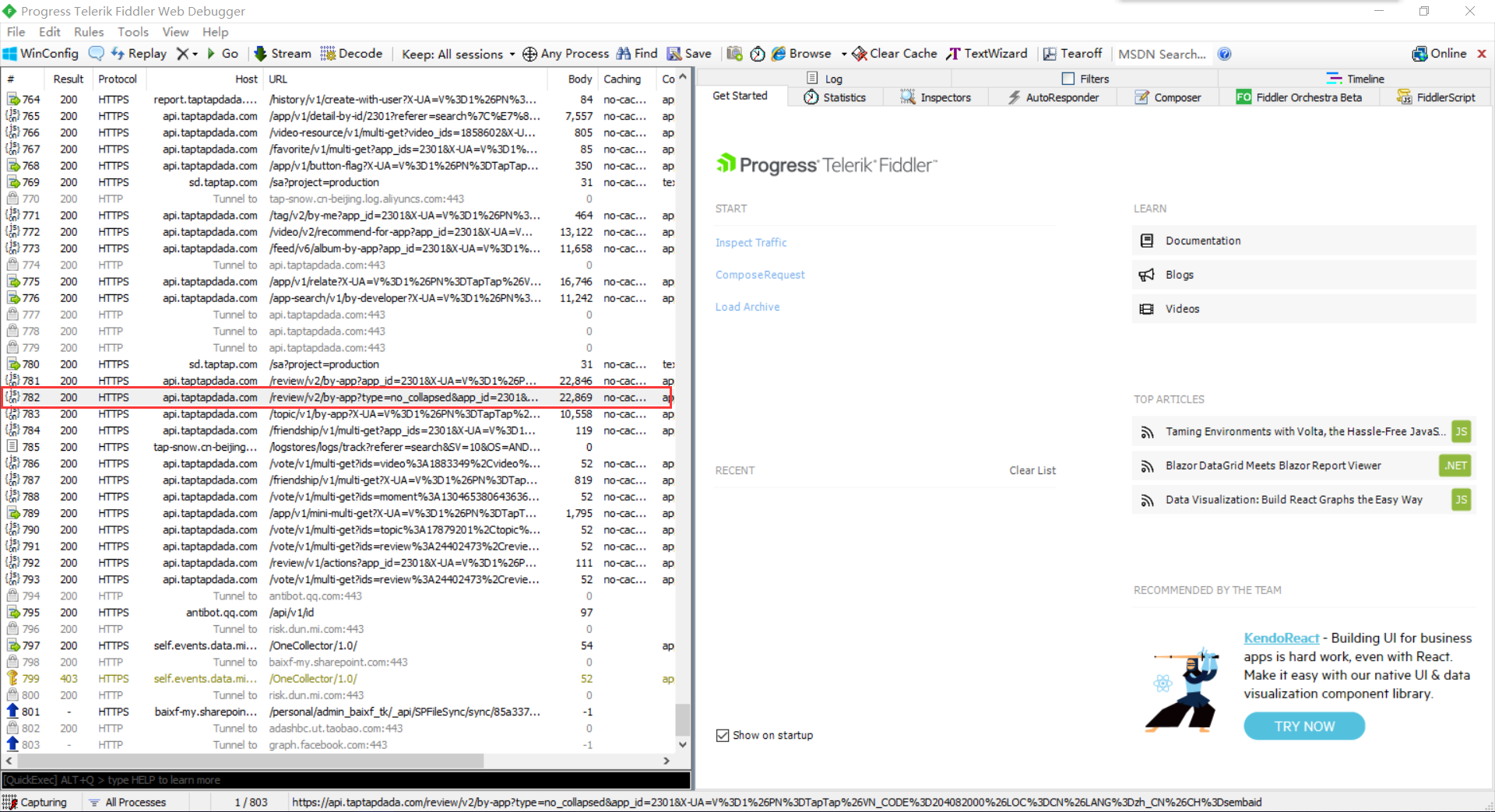
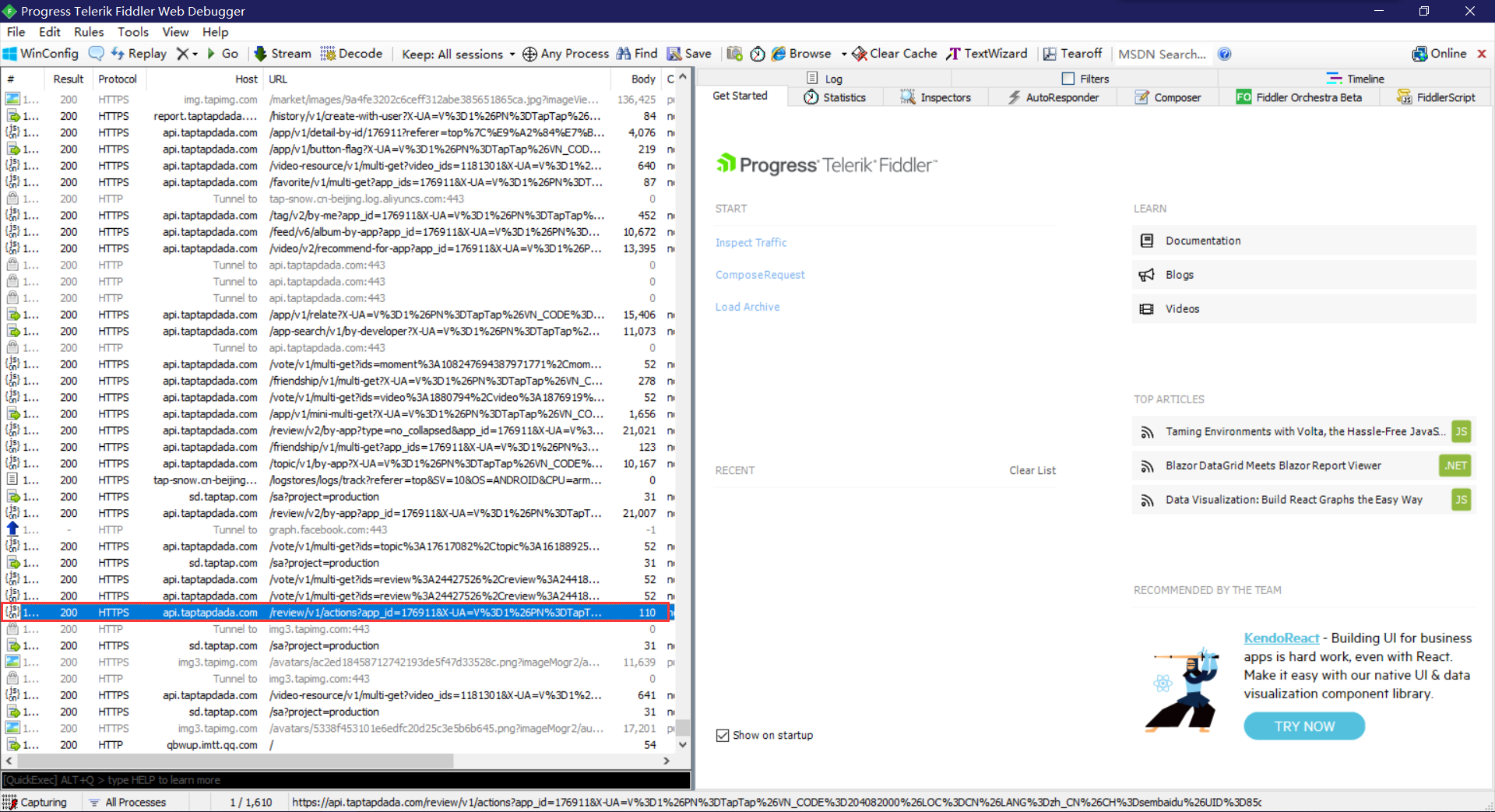
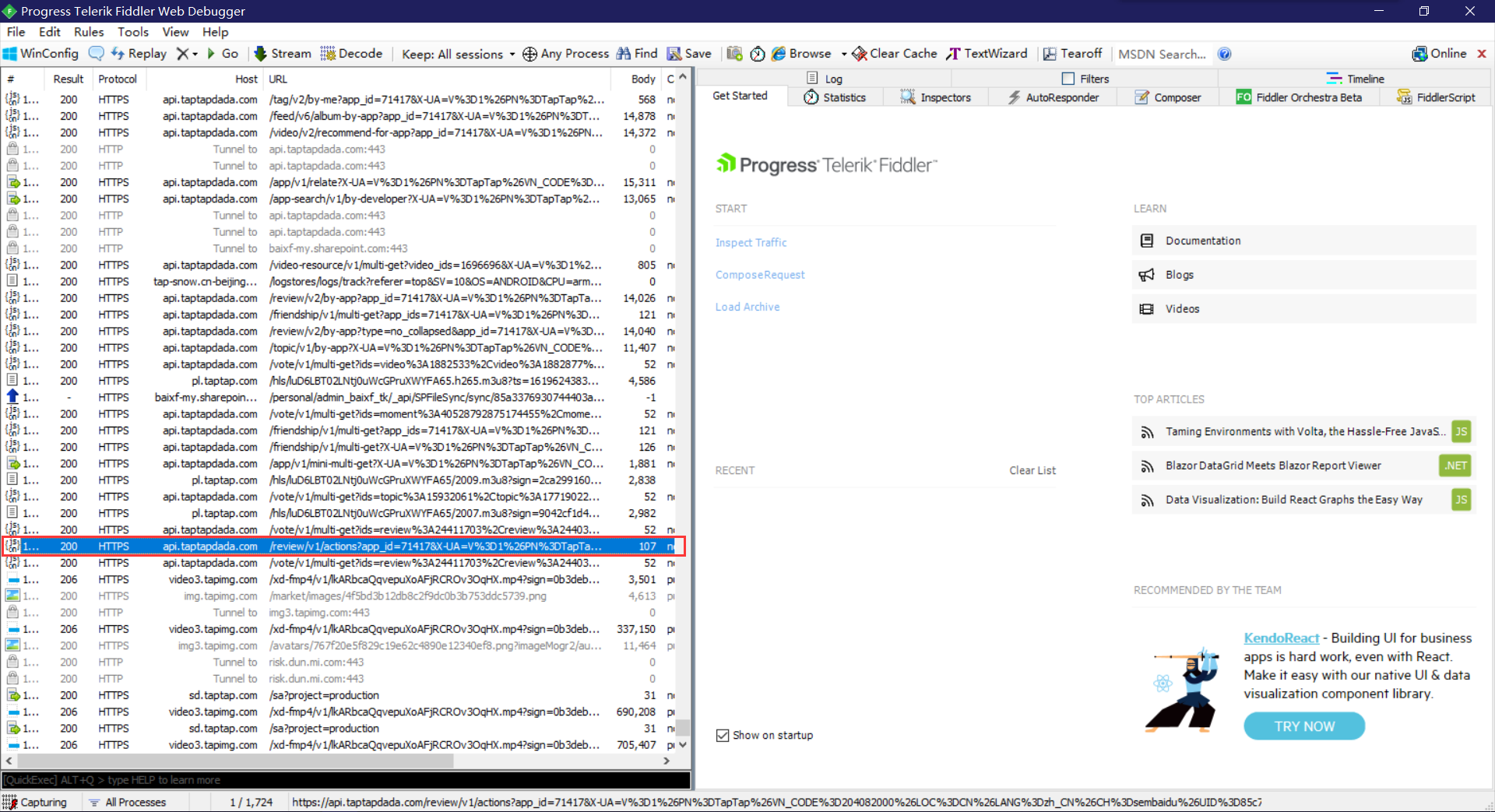
TAPTAP评论数据通过JSON返回,使用python中的Requests库非常容易就可以提取里面的内容。下面这幅图是Fiddler抓包时看到的数据:
运行环境
请在python环境下运行,本次程序的开发环境为python 3.8.1
基本功能
这个程序根据你提供的游戏id,按评论最近更新时间,自动抓取每条完整的游戏评论和它的关联信息,存放到csv文件中。
- 前置准备: 如果你将csv文件的保存路径设置在C盘,最好手动建立路径,否则可能会出现premission dennied,抓取的数据保存不成功
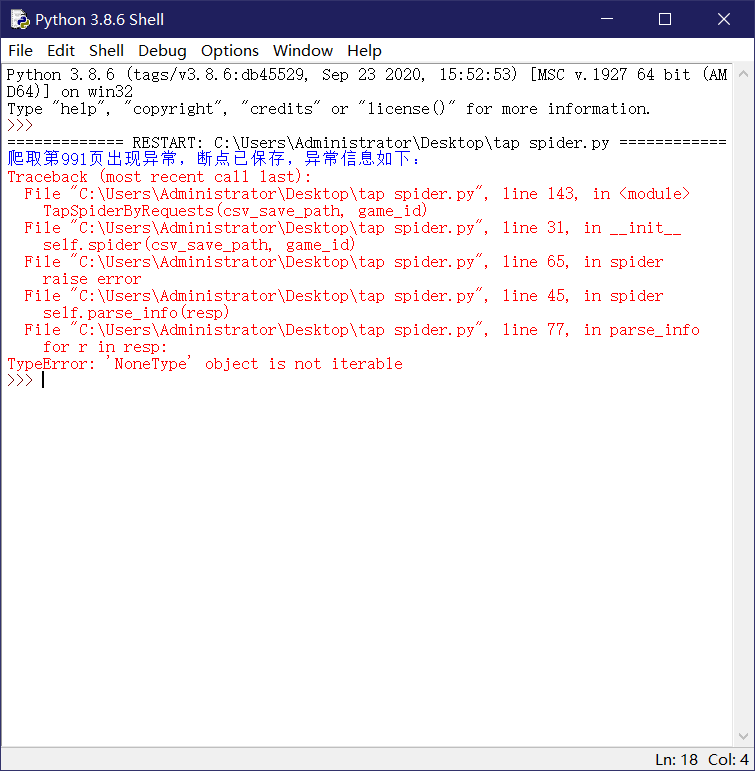
- 爬虫运行: 最大抓取页数为990页,由于taptap的设置,单个游戏在990以后的评论数据无法访问。爬取过程中出错,重新运行程序,程序会自动在断点位置续爬
- 爬虫结束: 达到上限,程序报页面无法打开,数据已在csv文件中保存
抓包获取游戏id
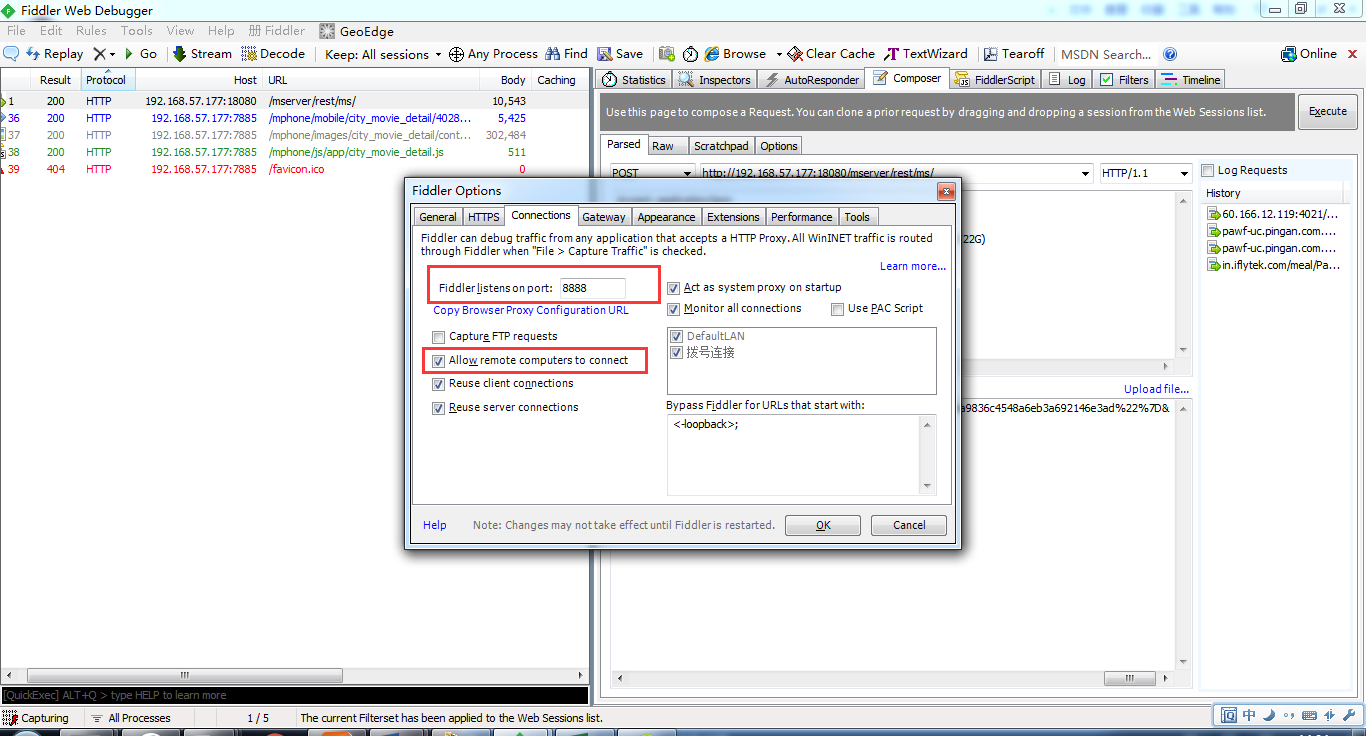
因为fiddler抓包的原理就是通过代理,所以被测终端需要和安装fiddler的电脑在同一个局域网中。
开启Fiddler的远程连接,Fiddler 主菜单 Tools -> Fiddler Options…-> Connections页签,选中Allowremote computers to connect,并记住端口号为8888,等会设置手机代理时需要。设置好后重启fiddler保证设置生效。设置如下:
查看电脑IP,在CMD中输入ipconfig或者直接在开热点设备上查看连接设备的ip。
在手机侧设置代理
设置-WLAN,找到连接的wifi-选择修改网络-勾选高级选项,选择代理为手动,填入代理服务器为自己电脑IP,端口填入刚刚记住的8888。iPhone则可以在对应wifi的设置中直接配置HTTP代理。
- 开始抓包
在手机上对APP进行操作,从fiddler上即可看到对应的网络请求信息与游戏id。
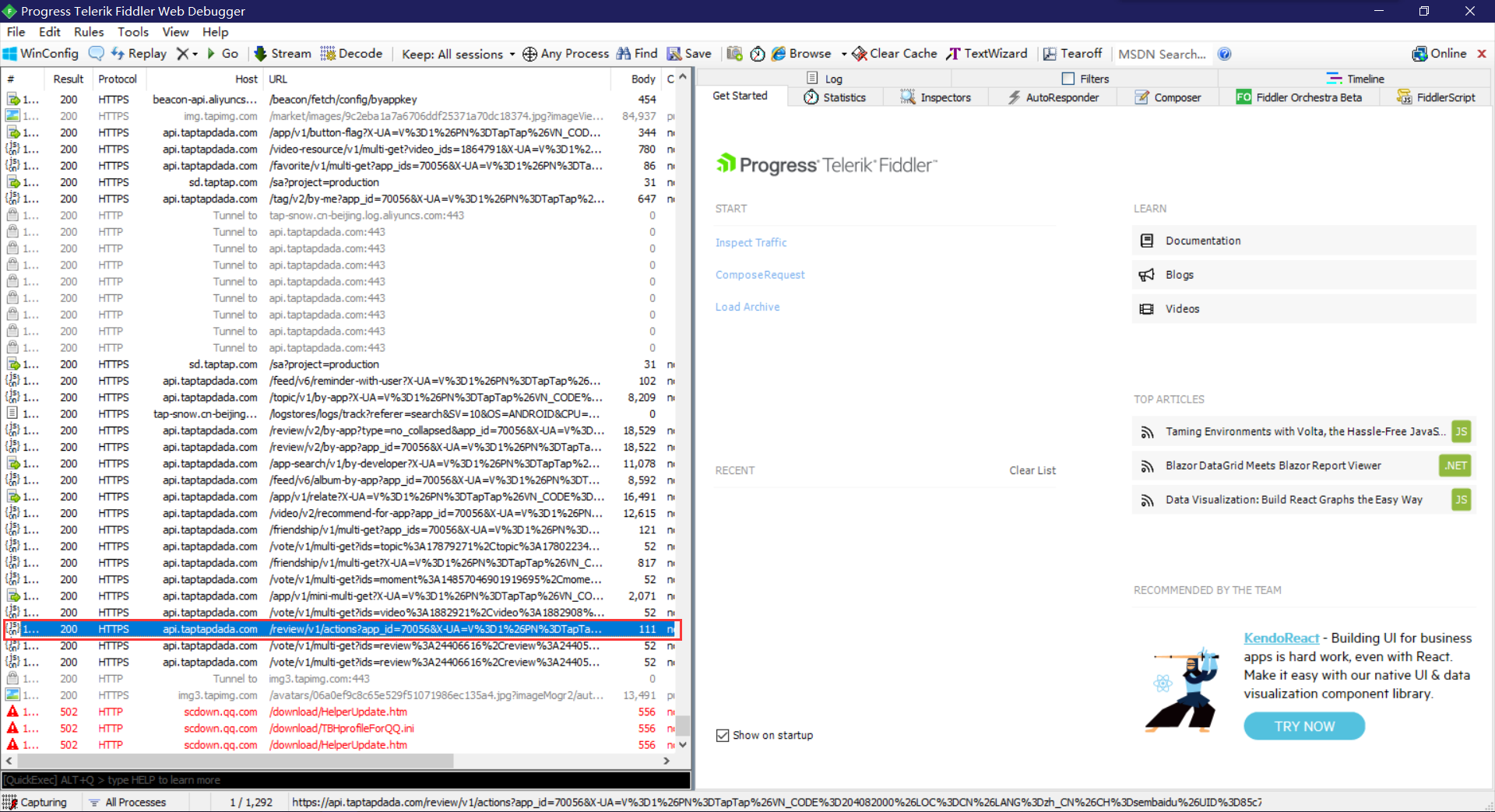
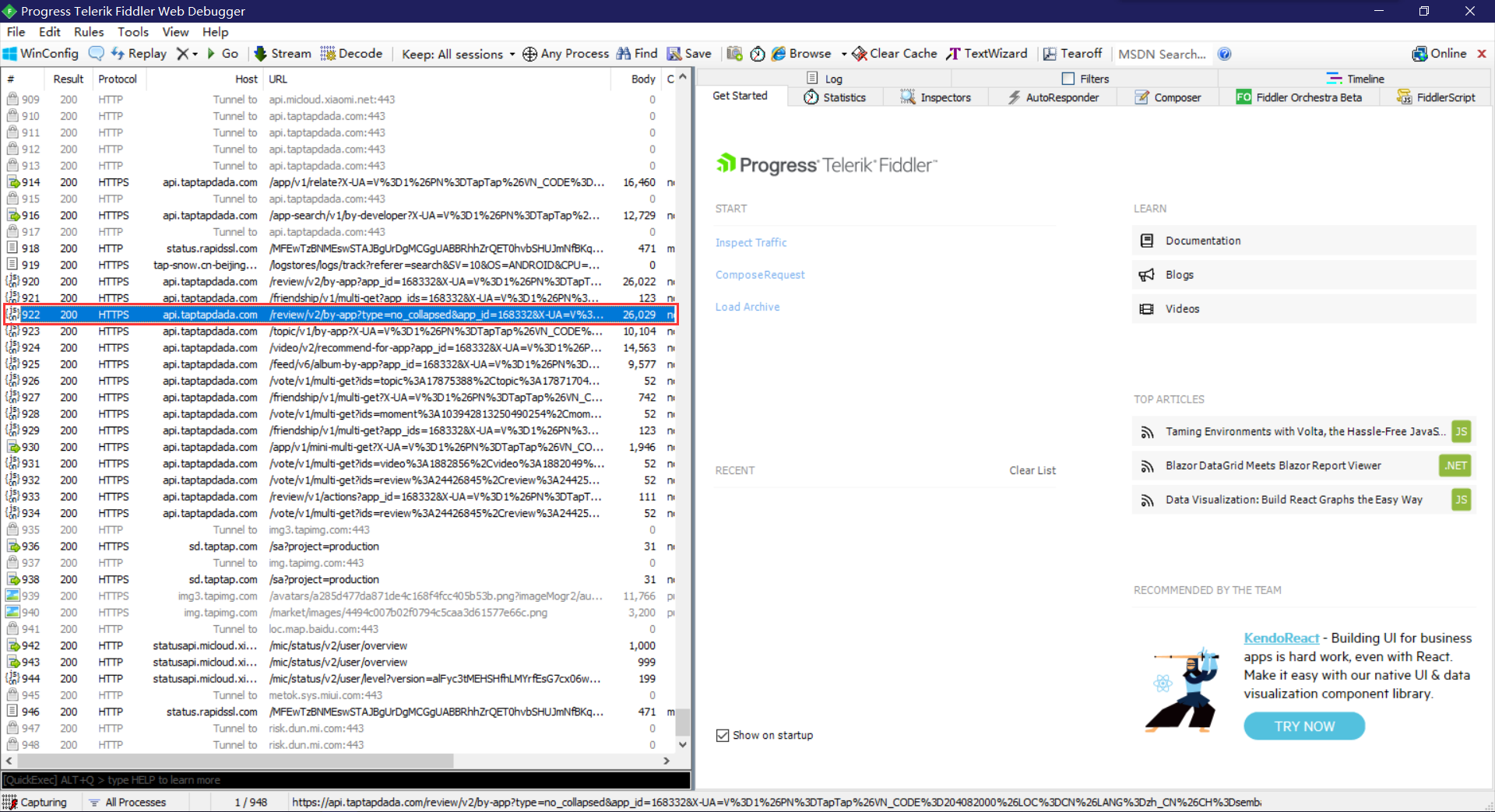
断点续传
建立断点txt文件,在因网络等原因中断时,重启程序,可以在断点处续爬,在中断时,已缓存的数据将保存至csv
1
2
3
4
5
6
7
8
9
10
| def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
|
爬虫休眠
文明爬虫,虽未发现反爬,但爬完每个页面后暂停0-2秒,减轻服务器负担
1
2
3
4
| import random
import time
pause = random.uniform(0, 2)
time.sleep(pause)
|
编码转换
python中比较容易出现编码问题,在中文环境下更甚,评论里可能会有无法打印的字符,虽然不影响数据下载,但容易影响后续处理。先把数据进行gbk编码,丢弃无法识别的字符,再进行解码,最后将数据保存为utf-8格式,上面的问题就不存在啦~
1
| review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
|
其他信息:
每页10条数据,每个游戏的评论最多可爬990页,超过990页,TAPTAP拒绝访问。
程序将采集到的数据存放至你指定路径的csv中。
爬虫完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| import requests
import os
import re
import random
import time
import csv
HEADERS = {'Host': 'api.taptapdada.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.10.0'}
BASE_URL = 'https://api.taptapdada.com/review/v1/by-app?sort=new&app_id={}' \
'&X-UA=V%3D1%26PN%3DTapTap%26VN_CODE%3D593%26LOC%3DCN%26LANG%3Dzh_CN%26CH%3Ddefault' \
'%26UID%3D8a5b2b39-ad33-40f3-8634-eef5dcba01e4%26VID%3D7595643&from={}'
STOP_POINT_FILE = 'stop_point.txt'
class TapSpiderByRequests:
def __init__(self, csv_save_path, game_id):
"""
获取断点,激活爬虫
"""
self.start_from = self.resume()
self.reviews = []
self.spider(csv_save_path, game_id)
def spider(self, csv_save_path, game_id):
"""
发送请求,验证访问状态
:return: 网页返回的json数据
"""
end_from = self.start_from + 300
for i in range(self.start_from, end_from+1, 10):
url = BASE_URL.format(game_id, i)
try:
resp = requests.get(url, headers=HEADERS).json()
resp = resp.get('data').get('list')
self.parse_info(resp)
print('=============已爬取第 %d 页=============' % int(i/10))
if i != end_from:
print('爬虫等待中...')
pause = random.uniform(0, 2)
time.sleep(pause)
print('等待完成,准备翻页。')
else:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i+10))
except Exception as error:
with open(STOP_POINT_FILE, 'w') as f:
f.write(str(i))
print('爬取第%i页出现异常,断点已保存,异常信息如下:' % int(i/10))
raise error
exit()
self.write_csv(csv_save_path, self.reviews)
def parse_info(self, resp):
"""
:param resp: 本页返回的json数据
:return: 将本页评论信息追加至REVIEWS列表
"""
for r in resp:
review = {}
review['id'] = r.get('id')
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')
review['updated_time'] = r.get('updated_time')
review['device'] = r.get('device').encode('gbk', 'ignore').decode('gbk')
review['spent'] = r.get('spent')
review['stars'] = r.get('score')
content = r.get('contents').get('text').strip()
review['contents'] = re.sub('<br />| ', '', content).encode('gbk', 'ignore').decode('gbk')
review['ups'] = r.get('ups')
review['downs'] = r.get('downs')
self.reviews.append(review)
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from
def write_csv(self, full_path, reviews):
"""
:param full_path: csv保存的完整路径
:param reviews: 列表形式的评论信息
"""
title = reviews[0].keys()
path, file_name = os.path.split(full_path)
if os.path.exists(full_path):
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writerows(reviews)
else:
try:
os.mkdir(path)
except Exception:
print('路径已存在,或未获得建立路径的权限。请检查路径是否存在,或手动建立路径。')
with open(full_path, 'a+', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, title)
writer.writeheader()
writer.writerows(reviews)
if __name__ == '__main__':
csv_save_path = r'.\data\tap_reviews.csv'
game_id = 2301
for i in range(33):
TapSpiderByRequests(csv_save_path, game_id)
|
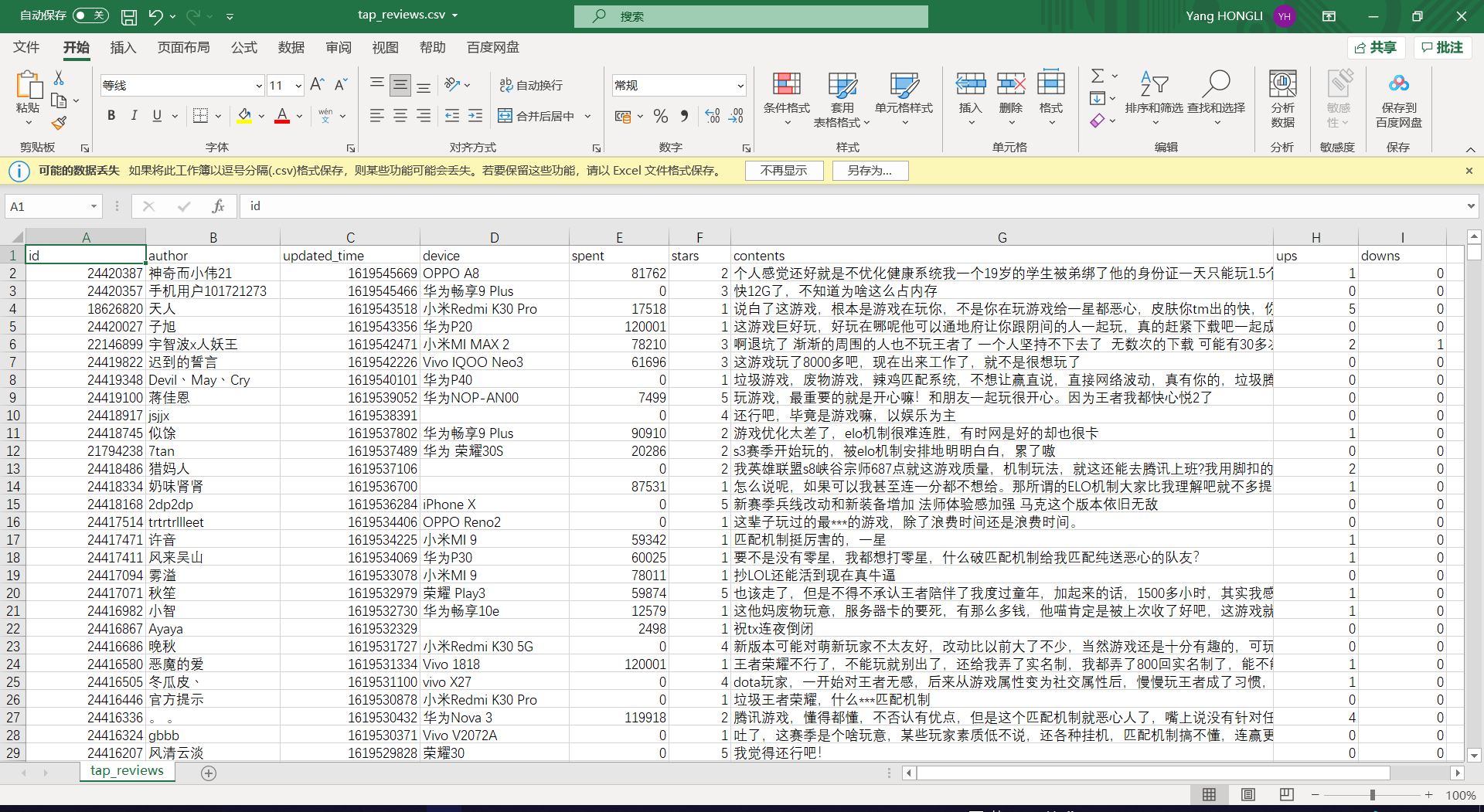
爬虫数据文档
二、数据清洗
这一步主要为数据可视化服务,使用pandas库可以很方便地进行数据清洗。
新增列
评论热度
点赞数和点踩数的总和,进行归一化表示
1
2
| data['heat'] = data['ups'] + data['downs']
data['heat'] = (data['heat'] - data['heat'].min()) / (data['heat'].max() - data['heat'].min())
|
评分
评论标星的2倍,标星范围1-5,评分范围2-10
1
| data['score'] = data['stars']*2
|
评论净支持数
1
| data['net_support'] = data['ups'] - data['downs']
|
转换
时间戳转换日期
为了让pyecharts识别出时间标签,需要进行日期转换
1
2
| import time
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))
|
替换
替换游玩时间中的0值:
实际情况下,玩家不太可能在未游玩的情况下评论(或者说这些评论意义不大),将游玩时间0替换为缺失是合理的,当进行相关维度的可视化,这些缺失值将不会被考虑
1
| data['spent'] = data['spent'].replace(0, np.nan)
|
删除
用正则表达式删除无意义字符
一些同学发评论比较喜欢用颜表情,但在爬虫过程中,gbk编码下无法全部显示,只能删掉意义不明的那另一半
1
2
3
| import re
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))
|
删除无意义的列数据
1
2
| import pandas as pd
data.drop(['ups', 'downs'], axis=1, inplace=True)
|
清洗完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import pandas as pd
import time
import re
import numpy as np
csv_path = r'.\data\tap_reviews.csv'
clean_path = r'.\data\tap_reviews-extend cleaned.csv'
data = pd.read_csv(csv_path, header=0, index_col='id')
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))
data['net_support'] = data['ups'] - data['downs']
data['heat'] = data['ups'] + data['downs']
data['heat'] = (data['heat'] - data['heat'].min()) / (data['heat'].max() - data['heat'].min())
data['score'] = data['stars']*2
data['spent'] = data['spent'].replace(0, np.nan)
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))
data.drop(['ups', 'downs'], axis=1, inplace=True)
data.to_csv(clean_path, encoding='utf_8_sig')
|
清洗后数据文档
三、可视化
查看数据分布情况,通过对评论的长度分析,利用星级评论情感分布分析,一定程度上查看玩家对游戏整体的满意度。
从时间、设备、玩家印象维度可视化评论数据,这一步使用pyecharts库。pyecharts库是python生成Eharts图表的轮子,官方文档中就有 丰富的图表实例。颜值高,上手容易,入股不亏。
查看数据分布情况
查看评论长度分布
1
2
3
4
5
6
| data['contents_length'] = data['contents'].apply(lambda x: len(str(x)))
len_se = data.groupby('contents_length')['contents_length'].count()
sns.distplot(len_se, bins=20, hist=True, kde=True, rug=True)
plt.title('taptap评论长度分布')
plt.show()
print('评论长度的9/10分位数:', data['contents_length'].quantile(0.9))
|
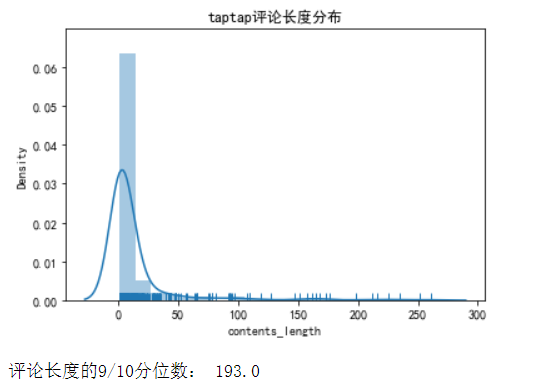
计算分位数发现,90%评论在193字内;密度图表明,评论长度集中在100字以内
查看评论情感分布
1
2
3
4
5
6
7
8
| positive = len(data['stars'][data['stars'] >= 4])
total = len(data['stars'])
negative = total - positive
sns.distplot(data['stars'], bins=5, kde=False, norm_hist=True)
plt.title('taptap评论情感分布')
plt.show()
print('正面评价: %d,占总数的%.2f%% 负面评价: %d, 占总数的%.2f%%' %
(positive, (positive/total*100), negative, (negative/total*100)))
|
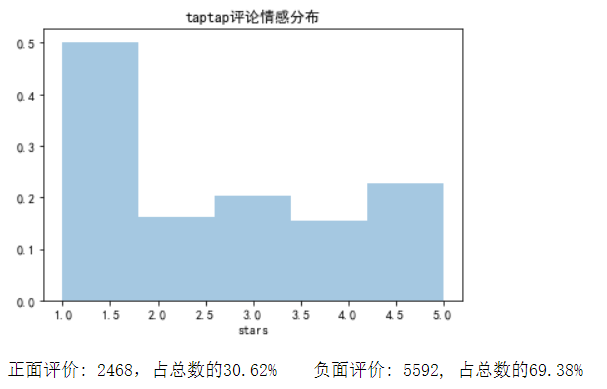
正面评价: 2468,占总数的30.62% ;负面评价: 5592, 占总数的69.38%。
时间维度的考察
王者荣耀每日评分均值变化
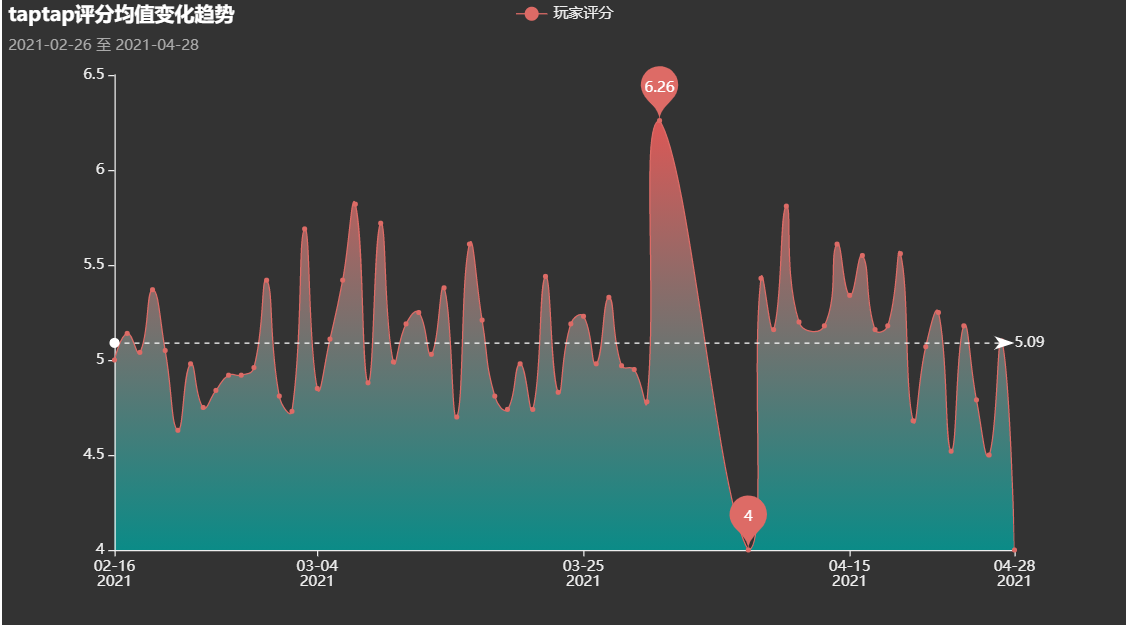
王者荣耀每日评分次数
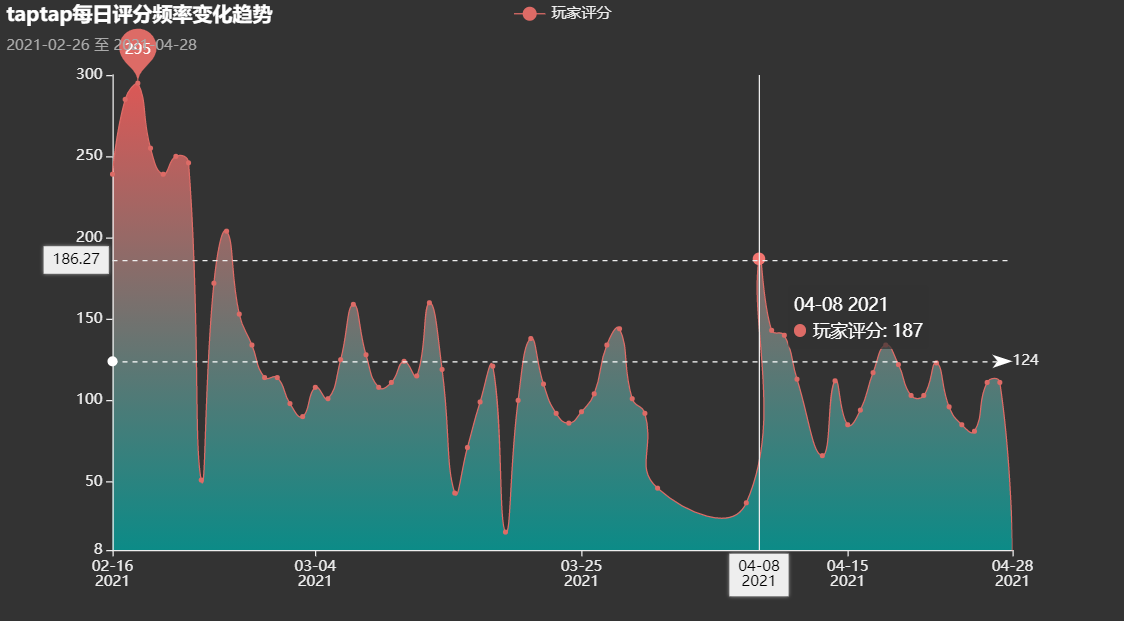
归因:04.08赛季更新

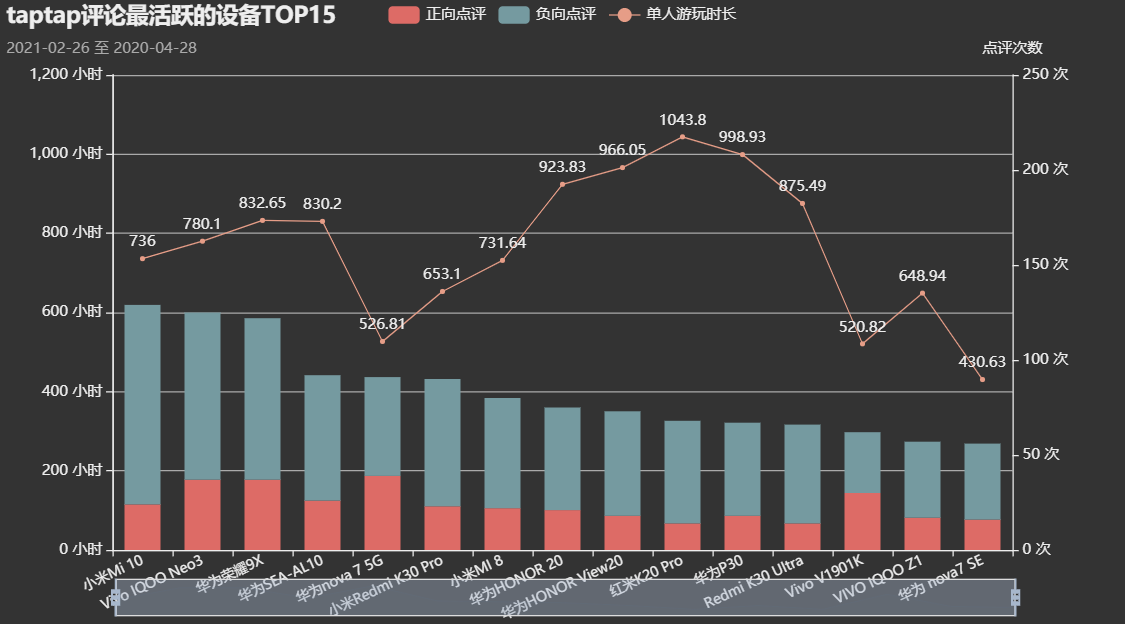
设备维度的考察
评论活跃设备Top15
评分较低设备Top10
玩家印象
使用文本挖掘的预处理方法对TOP500支持度和热度达到0.5的评论进行处理,得到了玩家对这个游戏的关键评价

可视化完整代码
在线查看网页
四、后记
对游戏的评价星数并不能真实的反映每个玩家对游戏的感情态度,因此我们还需要对评论数据进行数据挖掘、建立LSTM模型并对模型进行评价。
参考文献